ZTE Communications ›› 2025, Vol. 23 ›› Issue (3): 96-110.DOI: 10.12142/ZTECOM.202503011
• Research Papers • Previous Articles
HE Shuai1, LIU Limin1, WANG Zhanli2, LI Jinliang2, MAO Xiaojun2, MING Anlong1( )
)
Received:2024-11-13
Online:2025-09-25
Published:2025-09-11
About author:HE Shuai is a postdoctoral researcher in computer science at Beijing University of Posts and Telecommunications (BUPT), China. His research interests include image processing and image aesthetics assessment.Supported by:HE Shuai, LIU Limin, WANG Zhanli, LI Jinliang, MAO Xiaojun, MING Anlong. M+MNet: A Mixed-Precision Multibranch Network for Image Aesthetics Assessment[J]. ZTE Communications, 2025, 23(3): 96-110.
Add to citation manager EndNote|Ris|BibTeX
URL: https://zte.magtechjournal.com/EN/10.12142/ZTECOM.202503011

Figure 1 Visualizations of feature map activations generated via Grad-CAM[5]. Our model was pretrained on ImageNet[6] to initialize the weights: (a) Background and foreground information in the image correspond to low and high activations in the original feature map; (b) by copying a small part of the salient region to each of the four corners, the attention area is enlarged; (c) the proposed data augmentation method Corner Grid can be used to markedly increase the attention area

Figure 2 Visualization of images in the AVA dataset with a large absolute error between the ground truth and the predicted score (absolute error ≥ 1)

Figure 3 Samples selected from the AVA dataset, along with plots of their ground-truth score distributions

Figure 4 Activation maps comparing benchmark IAA models (Table 1) and our proposed method through fused 2D feature maps of the last layers of these models

Figure 5 Comparison of conventional mixed-precision training[15, 39] and our training method: Overflowed batches are skipped until stable gradients trigger phase transition

Figure 6 Overall architecture of the proposed MNet

Figure 7 Different activation maps are obtained when the pooling methods in NIMA are replaced with the proposed BackPool and ForePool methods, or with the traditional average and max pooling methods

Figure 8 Mixed-precision training process

Figure 9 Proposed three-stage training strategy: warm-up (ImageNet→AVA), mixed-precision training (FP32+FP16) with Corner Grid augmentation, and padding refinement
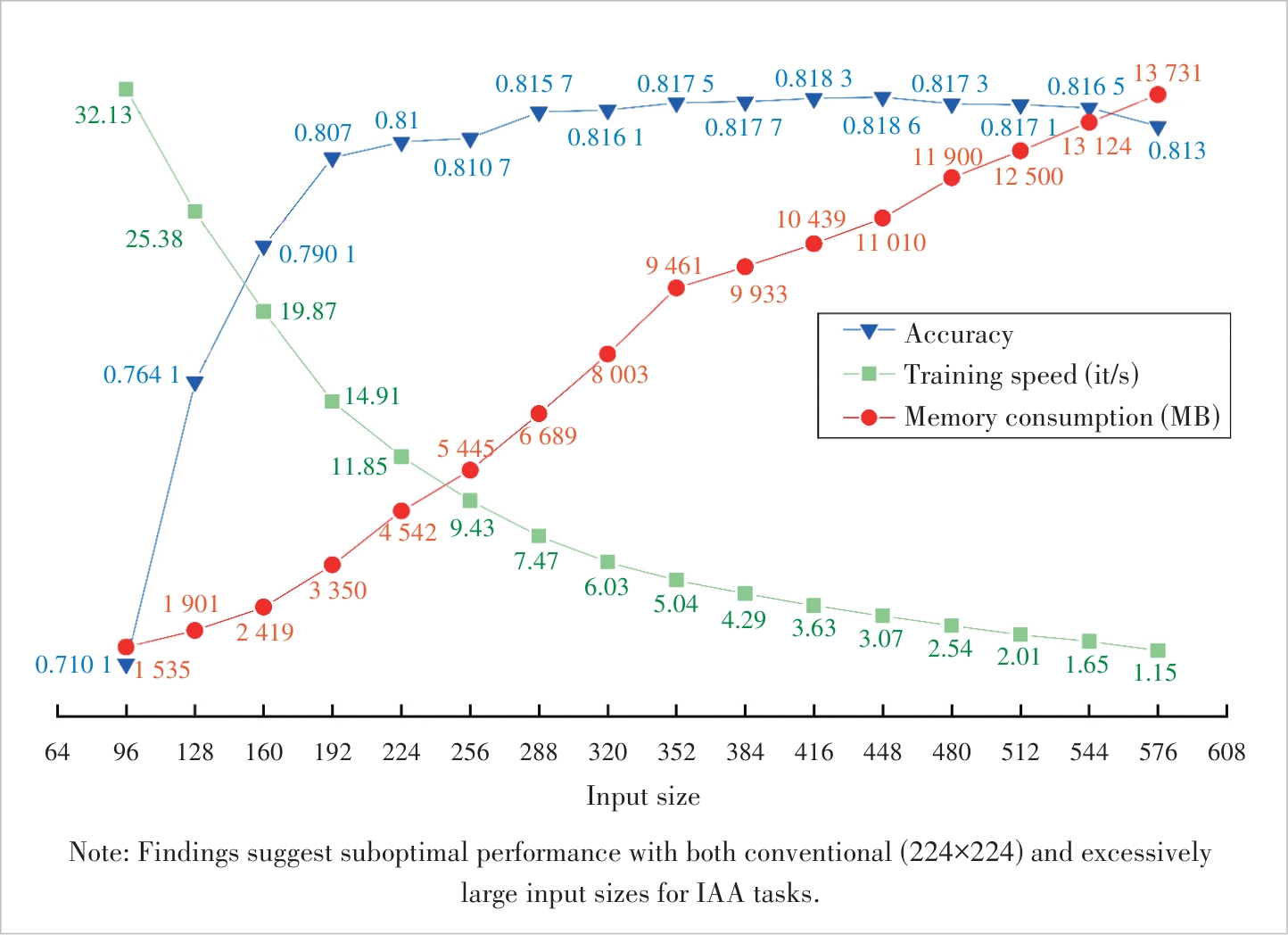
Figure 10 Effects of input size variation (AVA dataset, NIMA model) on accuracy, training speed, and memory consumption

Visualization of images with (a) small and (b) large absolute errors between the ground-truth and predicted (in parentheses) scores

Table 2. Performance comparison of SRCC results of the SOTA models for personalized aesthetics assessment on the FLICKR-AES dataset

Figure 12 Activation maps obtained when using Corner Grid with NIMA

Table 5. Performance of different architectures on the background-sensitive samples in AVA. We tested our model and NIMA with various pooling methods and Corner Grid
| Method | SRCC↑ | LCC↑ | Acc↑ |
|---|---|---|---|
| NIMA (EMD)[ | 0.612 | 0.636 | 0.815 |
| NIMA (Re-EMD)[ | 0.633 | 0.641 | 0.819 |
| UIAA (EMD)[ | 0.719 | 0.720 | 0.808 |
| UIAA (Re-EMD)[ | 0.723 | 0.731 | 0.817 |
| HGCN (EMD)[ | 0.665 | 0.687 | 0.846 |
| HGCN (Re-EMD)[ | 0.689 | 0.692 | 0.838 |
| M+MNet (EMD) | 0.762 | 0.766 | 0.822 |
| M+MNet (Re-EMD) | 0.770 | 0.785 | 0.824 |
Table 6 Comparison of the performance achieved by retraining all the IAA models on AVA using the Re-EMD loss in place of the EMD loss
| Method | SRCC↑ | LCC↑ | Acc↑ |
|---|---|---|---|
| NIMA (EMD)[ | 0.612 | 0.636 | 0.815 |
| NIMA (Re-EMD)[ | 0.633 | 0.641 | 0.819 |
| UIAA (EMD)[ | 0.719 | 0.720 | 0.808 |
| UIAA (Re-EMD)[ | 0.723 | 0.731 | 0.817 |
| HGCN (EMD)[ | 0.665 | 0.687 | 0.846 |
| HGCN (Re-EMD)[ | 0.689 | 0.692 | 0.838 |
| M+MNet (EMD) | 0.762 | 0.766 | 0.822 |
| M+MNet (Re-EMD) | 0.770 | 0.785 | 0.824 |
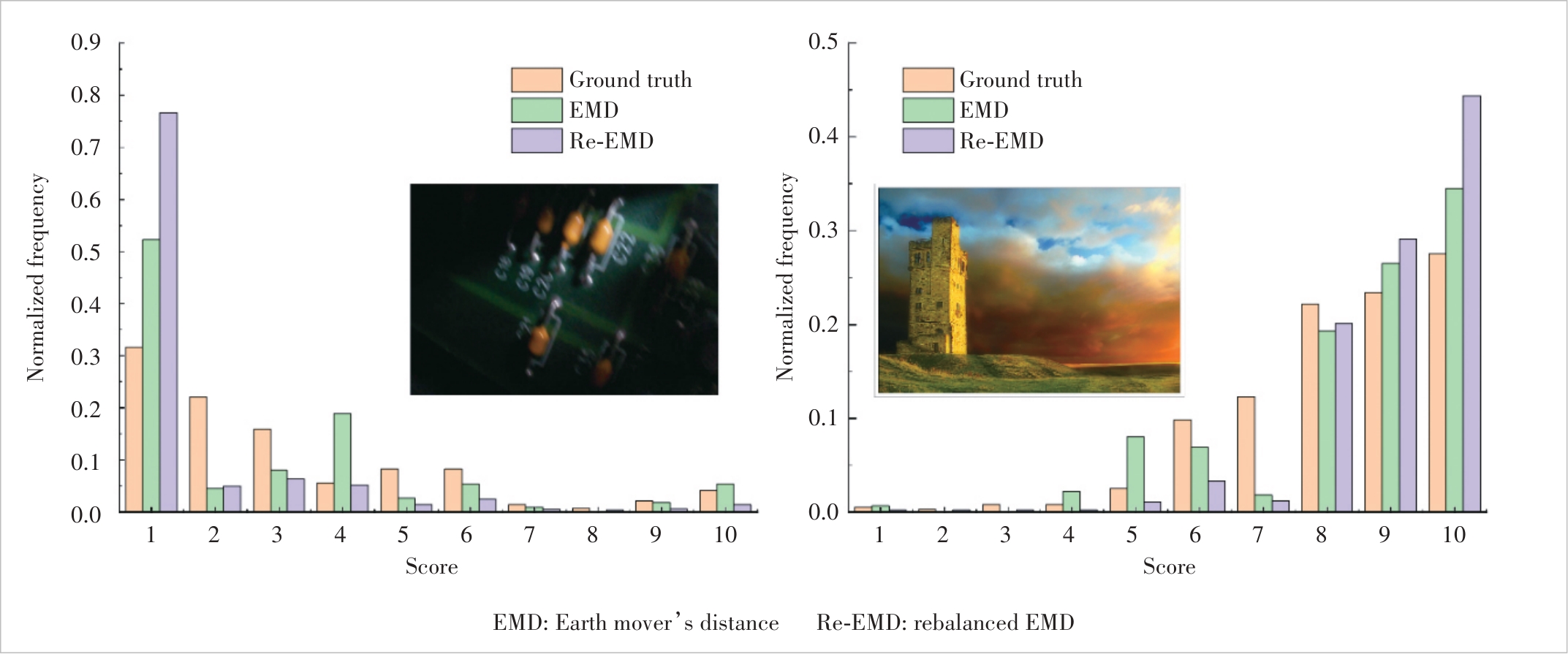
Figure 13 Results of normalizing (0–1) distributions of the ground truth and losses contributed by each score based on EMD and Re-EMD losses during training
| [1] | ITTI L, KOCH C. Computational modelling of visual attention [J]. Nature reviews neuroscience, 2001, 2(3): 194–203. DOI: 10.1038/35058500 |
| [2] | SIAGIAN C, ITTI L. Rapid biologically-inspired scene classification using features shared with visual attention [J]. IEEE transactions on pattern analysis and machine intelligence, 2007, 29(2): 300–312. DOI: 10.1109/TPAMI.2007.40 |
| [3] | BIEDERMAN I. Do background depth gradients facilitate object identification? [J]. Perception, 1981, 10(5): 573–578. DOI: 10.1068/p100573 |
| [4] | POTTER M C. Meaning in visual search [J]. Science, 1975, 187(4180): 965–966. DOI: 10.1126/science.1145183 |
| [5] | SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization [C]//Proc. IEEE International Conference on Computer Vision (ICCV). IEEE, 2017: 618–626. DOI: 10.1109/ICCV.2017.74 |
| [6] | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]//Proc. IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009: 248–255. DOI: 10.1109/CVPR.2009.5206848 |
| [7] | TALEBI H, MILANFAR P. NIMA: neural image assessment [J]. IEEE transactions on image processing, 2018, 27(8): 3998–4011. DOI: 10.1109/TIP.2018.2831899 |
| [8] | MURRAY N, MARCHESOTTI L, PERRONNIN F. AVA: a large-scale database for aesthetic visual analysis [C]//Proc. IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2012: 2408–2415. DOI: 10.1109/CVPR.2012.6247954 |
| [9] | GAO Z T, WANG L M, WU G S. LIP: local importance-based pooling [C]//Proc. IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2019: 3355–3364. DOI: 10.1109/iccv.2019.00345 |
| [10] | ZHONG Z, ZHENG L, KANG G L, et al. Random erasing data augmentation [C]//Proc. AAAI Conference on Artificial Intelligence. AAAI, 2020: 13001–13008. DOI: 10.1609/aaai.v34i07.7000 |
| [11] | DEVRIES T, TAYLOR G W. Improved regularization of convolutional neural networks with cutout [EB/OL]. (2017-08-15)[2024-01-23]. |
| [12] | SINGH K K, LEE Y J. Hide-and-seek: forcing a network to be meticulous for weakly-supervised object and action localization [C]//Proc. IEEE International Conference on Computer Vision (ICCV). IEEE, 2017: 3544–3553. DOI: 10.1109/ICCV.2017.381 |
| [13] | HE K M, CHEN X L, XIE S N, et al. Masked autoencoders are scalable vision learners [EB/OL]. (2021-11-11)[2024-03-20]. |
| [14] | HOSU V, GOLDLUCKE B, SAUPE D. Effective aesthetics prediction with multi-level spatially pooled features [C]//Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019: 9375–9383. DOI: 10.1109/cvpr.2019.00960 |
| [15] | MICIKEVICIUS P, NARANG S, ALBEN J, et al. Mixed precision training [C]//Proc. International Conference on Learning Representations (ICLR). OpenReview, 2018. DOI: 10.48550/arXiv.1710.03740 |
| [16] | REN J, SHEN X H, LIN Z, et al. Personalized image aesthetics [C]//Proc. IEEE International Conference on Computer Vision (ICCV). IEEE, 2017: 638–647. DOI: 10.1109/ICCV.2017.76 |
| [17] | LUO Y W, TANG X O. Photo and video quality evaluation: focusing on the subject [C]//European Conference on Computer Vision. ECCV, 2008: 386–399. DOI: 10.1007/978-3-540-88690-7_29 |
| [18] | DATTA R, JOSHI D, LI J, et al. Studying aesthetics in photographic images using a computational approach [C]//European Conference on Computer Vision. ECCV, 2006: 288–301. DOI: 10.1007/11744078_23 |
| [19] | LU X, LIN Z, SHEN X H, et al. Deep multi-patch aggregation network for image style, aesthetics, and quality estimation [C]//Proc. IEEE International Conference on Computer Vision (ICCV). IEEE, 2015: 990–998. DOI: 10.1109/ICCV.2015.119 |
| [20] | LU X, LIN Z L, JIN H L, et al. RAPID: rating pictorial aesthetics using deep learning [C]//Proc. ACM International Conference on Multimedia. ACM, 2014: 457–466. DOI: 10.1145/2647868.2654926 |
| [21] | MA S, LIU J, CHEN C W. A-lamp: adaptive layout-aware multi-patch deep convolutional neural network for photo aesthetic assessment [C]//Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017: 722–731. DOI: 10.1109/CVPR.2017.84 |
| [22] | JIN X, WU L, LI X D, et al. ILGNet: inception modules with connected local and global features for efficient image aesthetic quality classification using domain adaptation [J]. IET computer vision, 2019, 13(2): 206–212. DOI: 10.1049/iet-cvi.2018.5249 |
| [23] | SHENG K K, DONG W M, MA C Y, et al. Attention-based multi-patch aggregation for image aesthetic assessment [C]//Proc. 26th ACM International Conference on Multimedia. ACM, 2018: 879–886. DOI: 10.1145/3240508.3240554 |
| [24] | KONG S, SHEN X H, LIN Z, et al. Photo aesthetics ranking network with attributes and content adaptation [C]// European Conference on Computer Vision. ECCV, 2016: 662–679. DOI: 10.1007/978-3-319-46448-0_40 |
| [25] | ZHANG X D, GAO X B, LU W, et al. Beyond vision: a multimodal recurrent attention convolutional neural network for unified image aesthetic prediction tasks [J]. IEEE transactions on multimedia, 2020, 23: 611–623. DOI: 10.1109/TMM.2020.2985526 |
| [26] | HOU L, YU C P, SAMARAS D. Squared earth mover's distance-based loss for training deep neural networks [EB/OL]. (2016-11-18)[2024-03-19]. |
| [27] | ZENG H, CAO Z S, ZHANG L, et al. A unified probabilistic formulation of image aesthetic assessment [J]. IEEE transactions on image processing, 2019, 29: 1548–1561. DOI: 10.1109/TIP.2019.2941778 |
| [28] | SHE D Y, LAI Y K, YI G X, et al. Hierarchical layout-aware graph convolutional network for unified aesthetics assessment [C]//Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2021: 8475–8484. DOI: 10.1109/cvpr46437.2021.00837 |
| [29] | CHEN Q Y, ZHANG W, ZHOU N, et al. Adaptive fractional dilated convolution network for image aesthetics assessment [C]//Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020: 14114–14123. DOI: 10.1109/cvpr42600.2020.01412 |
| [30] | MURRAY N, GORDO A. A deep architecture for unified aesthetic prediction [EB/OL]. (2017-08-16)[2024-03-19]. |
| [31] | ZHAO L, SHANG M M, GAO F, et al. Representation learning of image composition for aesthetic prediction [J]. Computer vision and image understanding, 2020, 199: 103024. DOI: 10.1016/j.cviu.2020.103024 |
| [32] | LI L D, ZHU H C, ZHAO S C, et al. Personality-assisted multi-task learning for generic and personalized image aesthetics assessment [J]. IEEE transactions on image processing, 2020, 29: 3898–3910. DOI: 10.1109/TIP.2020.2968285 |
| [33] | LYU P, FAN J, NIE X, et al. User-guided personalized image aesthetic assessment based on deep reinforcement learning [EB/OL]. (2021-06-14)[2024-03-19]. |
| [34] | ZHU H C, LI L D, WU J J, et al. Personalized image aesthetics assessment via meta-learning with bilevel gradient optimization [J]. IEEE transactions on cybernetics, 2022, 52(3): 1798–1811. DOI: 10.1109/TCYB.2020.2984670 |
| [35] | ZHANG X D, GAO X B, LU W, et al. A gated peripheral-foveal convolutional neural network for unified image aesthetic prediction [J]. IEEE transactions on multimedia, 2019, 21(11): 2815–2826. DOI: 10.1109/TMM.2019.2911428 |
| [36] | WANG W S, YANG S, ZHANG W S, et al. Neural aesthetic image reviewer [J]. IET computer vision, 2019, 13(8): 749–758. DOI: 10.1049/iet-cvi.2019.0361 |
| [37] | SAKURIKAR P, MEHTA I, BALASUBRAMANIAN V N, et al. RefocusGAN: scene refocusing using a single image [C]//European Conference on Computer Vision. ECCV, 2018: 519–535. DOI: 10.1007/978-3-030-01225-0_31 |
| [38] | SITZMANN V, DIAMOND S, PENG Y F, et al. End-to-end optimization of optics and image processing for achromatic extended depth of field and super-resolution imaging [J]. ACM transactions on graphics, 2018, 37(4): 1–13. DOI: 10.1145/3197517.3201333 |
| [39] | PURI R, KIRBY R, YAKOVENKO N, et al. Large scale language modeling: converging on 40GB of text in four hours [C]//Proc. IEEE International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD). IEEE, 2018: 290–297. DOI: 10.1109/SBAC-PAD.2018.00043 |
| [40] | COURBARIAUX M, BENGIO Y, DAVID J P. BinaryConnect: training deep neural networks with binary weights during propagations [C]//Proc. Advances in Neural Information Processing Systems (NeurIPS). Curran Associates, 2015: 3123–3131. DOI: 10.48550/arXiv.1511.00363 |
| [41] | HUBARA I, COURBARIAUX M, SOUDY D, et al. Quantized neural networks: training neural networks with low precision weights and activations [J]. Journal of machine learning research, 2017, 18(1): 6869–6898. DOI: 10.5555/3122009.3242014 |
| [42] | HE Q, WEN H, ZHOU S, et al. Effective quantization methods for recurrent neural networks [EB/OL]. (2016-11-30)[2024-03-19]. |
| [43] | ZHOU S, WU Y, NI Z, et al. DoReFa-Net: training low bitwidth convolutional neural networks with low bitwidth gradients [EB/OL]. (2016-06-20)[2024-03-19]. |
| [44] | SANDLER M, HOWARD A, ZHU M L, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]//Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2018: 4510–4520. DOI: 10.1109/CVPR.2018.00474 |
| [45] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]//Proc. Advances in Neural Information Processing Systems (NeurIPS). Curran Associates, 2017: 5998–6008. DOI: 10.5555/3295222.3295349 |
| [46] | ZHANG H, GOODFELLOW I J, METAXAS D N, et al. Self-attention generative adversarial networks [C]//Proc. International Conference on Machine Learning (ICML). PMLR, 2018: 7354–7363. DOI: 10.5555/3327757.3360384 |
| [47] | CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]//European Conference on Computer Vision. ECCV, 2018: 833–851. DOI: 10.1007/978-3-030-01234-2_49 |
| [48] | LIN M, CHEN Q, YAN S. Network in network [C]//Proc. International Conference on Learning Representations (ICLR). ICLR, 2014: 1–10. DOI: 10.48550/arXiv.1312.4400. |
| [49] | LIU D, PURI R, KAMATH N, et al. Composition-aware image aesthetics assessment [C]//Proc. Winter Conference on Applications of Computer Vision (WACV). IEEE, 2020: 3569–3578. DOI: 10.1109/WACV45572.2020.9093626 |
| [50] | BUCHSBAUM G. A spatial processor model for object colour perception [J]. Journal of the franklin institute, 1980, 310(1): 1–26. DOI: 10.1016/0016-0032(80)90058-7 |
| [51] | MAI L, JIN H L, LIU F. Composition-preserving deep photo aesthetics assessment [C]//Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2016: 497–506. DOI: 10.1109/CVPR.2016.60 |
| [52] | WANG G L, YAN J C, QIN Z. Collaborative and attentive learning for personalized image aesthetic assessment [C]//Proc. Twenty-Seventh International Joint Conference on Artificial Intelligence. IJCAI, 2018: 957–963. DOI: 10.24963/ijcai.2018/133 |
| [53] | KE J J, WANG Q F, WANG Y L, et al. MUSIQ: multi-scale image quality transformer [C]//Proc. IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2021: 5128–5137. DOI: 10.1109/ICCV48922.2021.00510 |
| [54] | HOSU V, LIN H H, SZIRANYI T, et al. KonIQ-10k: an ecologically valid database for deep learning of blind image quality assessment [J]. IEEE transactions on image processing, 2020, 29: 4041–4056. DOI: 10.1109/TIP.2020.2967829 |
| [1] | AI Bo, ZHANG Yuxin, YANG Mi, HE Ruisi, GUO Rongge. A Machine Learning-Based Channel Data Enhancement Platform for Digital Twin Channels [J]. ZTE Communications, 2025, 23(2): 20-30. |
| [2] | CHENG Jiaming, CHEN Wei, LI Lun, AI Bo. Efficient Spatio-Temporal Predictive Learning for Massive MIMO CSI Prediction [J]. ZTE Communications, 2025, 23(1): 3-10. |
| [3] | WANG Chongchong, LI Yao, WANG Beibei, CAO Hong, ZHANG Yanyong. Point Cloud Processing Methods for 3D Point Cloud Detection Tasks [J]. ZTE Communications, 2023, 21(4): 38-46. |
| [4] | GONG Panyin, ZHANG Guidong, ZHANG Zhigang, CHEN Xiao, DING Xuan. Research on Fall Detection System Based on Commercial Wi-Fi Devices [J]. ZTE Communications, 2023, 21(4): 60-68. |
| [5] | DENG Letian, ZHAO Yanru. Deep Learning-Based Semantic Feature Extraction: A Literature Review and Future Directions [J]. ZTE Communications, 2023, 21(2): 11-17. |
| [6] | LU Ping, SHENG Bin, SHI Wenzhe. Scene Visual Perception and AR Navigation Applications [J]. ZTE Communications, 2023, 21(1): 81-88. |
| [7] | FAN Guotian, WANG Zhibin. Intelligent Antenna Attitude Parameters Measurement Based on Deep Learning SSD Model [J]. ZTE Communications, 2022, 20(S1): 36-43. |
| [8] | GAO Zhengguang, LI Lun, WU Hao, TU Xuezhen, HAN Bingtao. A Unified Deep Learning Method for CSI Feedback in Massive MIMO Systems [J]. ZTE Communications, 2022, 20(4): 110-115. |
| [9] | ZHANG Jintao, HE Zhenqing, RUI Hua, XU Xiaojing. Spectrum Sensing for OFDMA Using Multicarrier Covariance Matrix Aware CNN [J]. ZTE Communications, 2022, 20(3): 61-69. |
| [10] | HE Hongye, YANG Zhiguo, CHEN Xiangning. Payload Encoding Representation from Transformer for Encrypted Traffic Classification [J]. ZTE Communications, 2021, 19(4): 90-97. |
| [11] | XUE Songyan, LI Ang, WANG Jinfei, YI Na, MA Yi, Rahim TAFAZOLLI, Terence DODGSON. To Learn or Not to Learn:Deep Learning Assisted Wireless Modem Design [J]. ZTE Communications, 2019, 17(4): 3-11. |
| [12] | ZHENG Xiaoqing, LU Yaping, PENG Haoyuan, FENG Jiangtao, ZHOU Yi, JIANG Min, MA Li, ZHANG Ji, JI Jie. Detecting Abnormal Start-Ups, Unusual Resource Consumptions of the Smart Phone: A Deep Learning Approach [J]. ZTE Communications, 2019, 17(2): 38-43. |
| [13] | ZHENG Xiaoqing, CHEN Jun, SHANG Guoqiang. Deep Neural Network-Based Chinese Semantic Role Labeling [J]. ZTE Communications, 2017, 15(S2): 58-64. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

