ZTE Communications ›› 2026, Vol. 24 ›› Issue (1): 72-80.DOI: 10.12142/ZTECOM.202601010
• Special Topic • Previous Articles Next Articles
Lu Ping1,2, Song Li3( ), Shi Wenzhe1,2, Lin Zonghao3, Ling Jun3
), Shi Wenzhe1,2, Lin Zonghao3, Ling Jun3
Received:2024-09-06
Online:2026-03-25
Published:2026-03-17
About author:Lu Ping is the Vice President of ZTE Corporation, Director of the R&D Project of the Technology Planning Department, and Deputy Executive Director of the National Key Laboratory of Mobile Network and Mobile Multimedia Technology. His research fields include immersive communication, cloud computing, big data, augmented reality, and multimedia service technologies. He has supported and participated in major national science and technology projects as well as national science and technology support projects, and has published numerous academic papers in related fields.Supported by:Lu Ping, Song Li, Shi Wenzhe, Lin Zonghao, Ling Jun. AED-NeRF: Audio-Driven and Emotion- Editing Dynamic Neural Radiance Fields for Expressive Talking Face Avatar[J]. ZTE Communications, 2026, 24(1): 72-80.
Add to citation manager EndNote|Ris|BibTeX
URL: https://zte.magtechjournal.com/EN/10.12142/ZTECOM.202601010
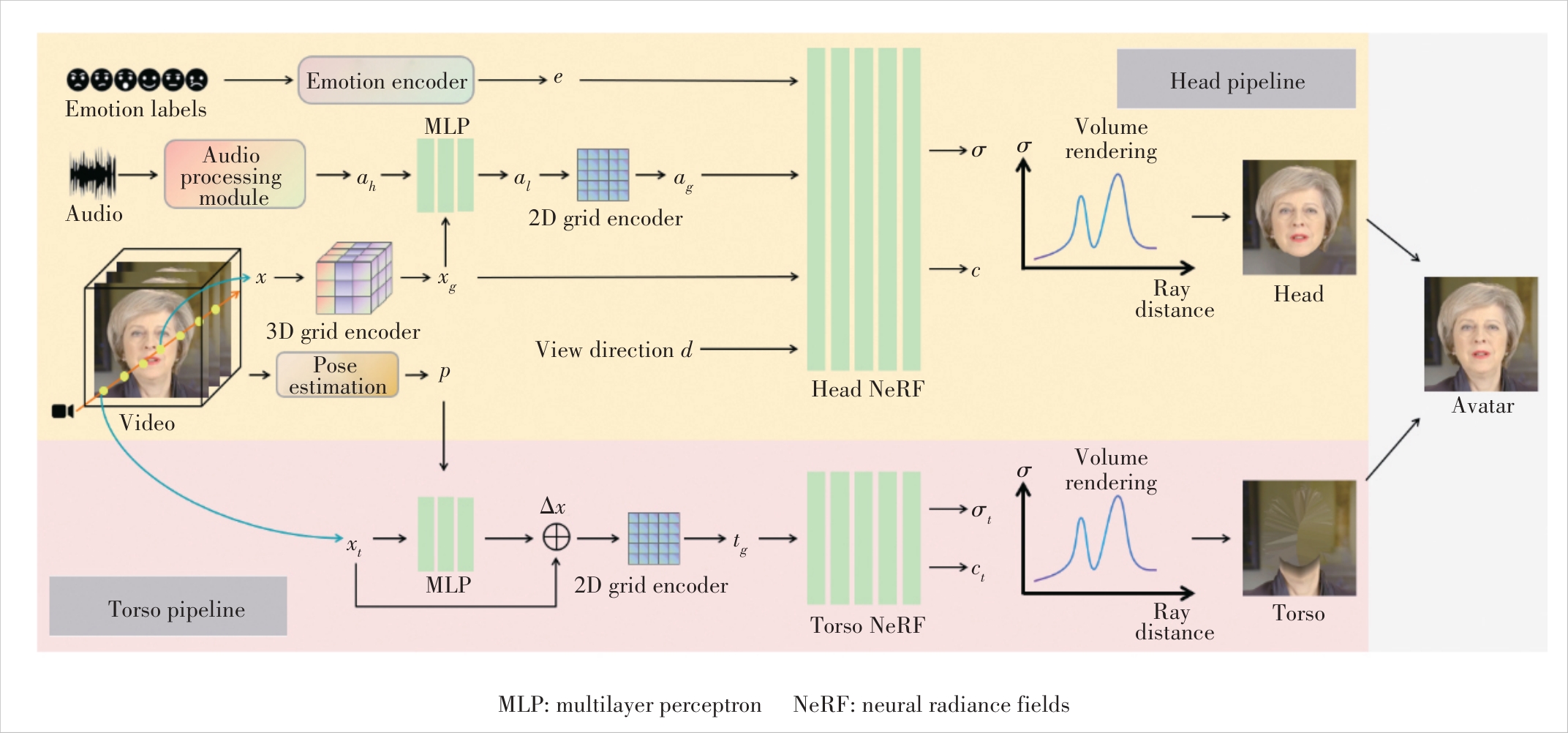
Figure 1 An overview of AED-NeRF framework
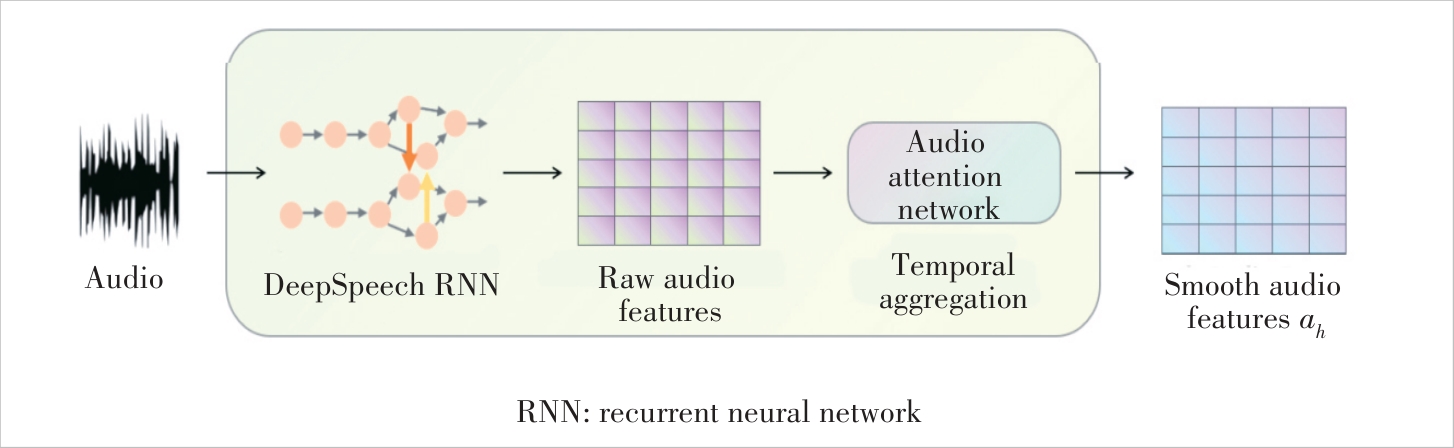
Figure 2 Audio processing module
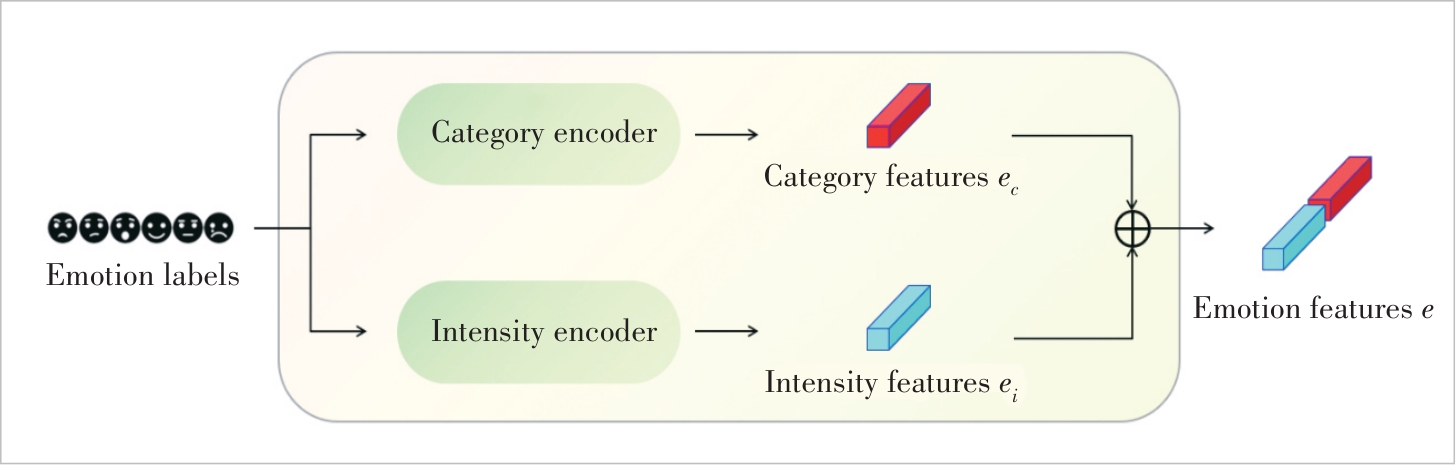
Figure 3 Illustration of emotion encoder
| Methods | Image Quality | Audio-Visual Synchronization | Rendering Speed | ||||
|---|---|---|---|---|---|---|---|
| PSNR↑ | LPIPS↓ | LMD↓ | Sync-C↑ | Sync-D↓ | Training time/h↓ | Inference speed/fps ↑ | |
| GT | ∞ | 0 | 0 | 8.897 | 6.325 | / | / |
| Wav2Lip | 30.90 | 0.139 | 3.311 | 7.898 | 6.694 | / | 15 |
| LSP | / | / | / | 5.181 | 8.637 | / | 25 |
| AD-NeRF | 28.79 | 0.101 | 3.245 | 3.944 | 10.603 | 36 | 0.09 |
| DFRF | 28.85 | 0.118 | 3.815 | 4.184 | 10.396 | 72 | 0.06 |
| AED-NeRF | 28.81 | 0.088 | 2.826 | 6.786 | 8.252 | 7 | 45 |
Table 1 Quantitative comparison under the self-driven setting
| Methods | Image Quality | Audio-Visual Synchronization | Rendering Speed | ||||
|---|---|---|---|---|---|---|---|
| PSNR↑ | LPIPS↓ | LMD↓ | Sync-C↑ | Sync-D↓ | Training time/h↓ | Inference speed/fps ↑ | |
| GT | ∞ | 0 | 0 | 8.897 | 6.325 | / | / |
| Wav2Lip | 30.90 | 0.139 | 3.311 | 7.898 | 6.694 | / | 15 |
| LSP | / | / | / | 5.181 | 8.637 | / | 25 |
| AD-NeRF | 28.79 | 0.101 | 3.245 | 3.944 | 10.603 | 36 | 0.09 |
| DFRF | 28.85 | 0.118 | 3.815 | 4.184 | 10.396 | 72 | 0.06 |
| AED-NeRF | 28.81 | 0.088 | 2.826 | 6.786 | 8.252 | 7 | 45 |
| Methods | ID A | ID B | ||
|---|---|---|---|---|
| Sync-C↑ | Sync-D↓ | Sync-C↑ | Sync-D↓ | |
| Wav2Lip | 8.748 | 7.623 | 8.208 | 7.193 |
| LSP | 3.979 | 9.656 | 5.097 | 8.477 |
| AD-NeRF | 3.259 | 10.123 | 3.037 | 10.526 |
| DFRF | 4.607 | 9.235 | 4.245 | 10.083 |
| AED-NeRF | 6.624 | 8.799 | 6.074 | 8.075 |
Table 2 Quantitative comparison under the cross-driven setting
| Methods | ID A | ID B | ||
|---|---|---|---|---|
| Sync-C↑ | Sync-D↓ | Sync-C↑ | Sync-D↓ | |
| Wav2Lip | 8.748 | 7.623 | 8.208 | 7.193 |
| LSP | 3.979 | 9.656 | 5.097 | 8.477 |
| AD-NeRF | 3.259 | 10.123 | 3.037 | 10.526 |
| DFRF | 4.607 | 9.235 | 4.245 | 10.083 |
| AED-NeRF | 6.624 | 8.799 | 6.074 | 8.075 |

Figure 4 Qualitative comparison under the self-driven setting

Figure 5 Qualitative comparison under the cross-driven setting

Figure 6 Neutral reference generated by (a) AD-NeRF and (b) AED-NeRF

Figure 7 Qualitative comparison of emotion editing

Figure 8 Benefiting from NeRF architecture and background disentanglement, our AED-NeRF can synthesize talking face avatars in novel views and support background editing

Figure 9 Ablation study on emotion modeling
| [1] | LeCun Y, Bengio Y, Hinton G. Deep learning [J]. Nature, 2015, 521(7553): 436–444. DOI: 10.1038/nature14539 |
| [2] | Creswell A, White T, Dumoulin V, et al. Generative adversarial networks: an overview [J]. IEEE signal processing magazine, 2018, 35(1): 53–65. DOI: 10.1109/MSP.2017.2765202 |
| [3] | Prajwal K R, Mukhopadhyay R, Namboodiri V P, et al. A lip sync expert is all you need for speech to lip generation in the wild [C]//The 28th ACM International Conference on Multimedia. ACM, 2020: 484–492. DOI: 10.1145/3394171.3413532 |
| [4] | Thies J, Elgharib M, Tewari A, et al. Neural voice puppetry: Audio⁃driven facial reenactment [PP/OL]. arxiv (2020⁃07⁃29) [2024⁃09⁃06]. |
| [5] | Guo Y D, Chen K Y, Liang S, et al. AD⁃NeRF: audio driven neural radiance fields for talking head synthesis [C]//International Conference on Computer Vision. IEEE, 2021: 5764–5774. DOI: 10.1109/ICCV48922.2021.00573 |
| [6] | Kumar R, Sotelo J, Kumar K, et al. Obamanet: photo⁃realistic lip⁃sync from text [PP/OL]. arxiv (2017⁃12⁃06) [2024⁃09⁃06]. |
| [7] | Wang J D, Qian X Y, Zhang M L, et al. Seeing what you said: talking face generation guided by a lip reading expert [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023: 14653–14662. DOI: 10.1109/CVPR52729.2023.01408 |
| [8] | Zhong W Z, Fang C W, Cai Y Q, et al. Identity⁃preserving talking face generation with landmark and appearance priors [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023: 9729–9738. DOI: 10.1109/CVPR52729.2023.00938 |
| [9] | Isola P, Zhu J Y, Zhou T H, et al. Image⁃to⁃image translation with conditional adversarial networks [C]//Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017: 5967–5976. DOI: 10.1109/CVPR.2017.632 |
| [10] | Eskimez S E, Zhang Y, Duan Z Y. Speech driven talking face generation from a single image and an emotion condition [J]. IEEE transactions on multimedia, 2022, 24: 3480–3490. DOI: 10.1109/TMM.2021.3099900 |
| [11] | Zhou Y, Han X T, Shechtman E, et al. MakeltTalk: speaker⁃aware talking⁃head animation [J]. ACM transactions on graphics, 2020, 39(6): 1–15. DOI: 10.1145/3414685.3417774 |
| [12] | Goodfellow I J, Pouget⁃Abadie J, Mirza M, et al. Generative adversarial nets [C]//The 28th International Conference on Neural Information Processing Systems. ACM, 2014: 2672–2680. DOI: 10.5555/2969033.2969125 |
| [13] | Yin F, Zhang Y, Cun X D, et al. StyleHEAT: one⁃shot high⁃resolution editable talking face generation via Pretrained StyleGAN [C]//European Conference on Computer Vision (ECCV). ECVA, 2022: 85–101. DOI: 10.1007/978-3-031-19790-1_6 |
| [14] | Doukas M C, Zafeiriou S, Sharmanska V. Headgan: video⁃and⁃audio⁃driven talking head synthesis: Vol. 1 [PP/OL]. arxiv (2021⁃08⁃23) [2024⁃09⁃06]. |
| [15] | Chen L L, Maddox R K, Duan Z Y, et al. Hierarchical cross⁃modal talking face generation with dynamic pixel⁃wise loss [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019: 7824–7833. DOI: 10.1109/CVPR.2019.00802 |
| [16] | Thies J, Elgharib M, Tewari A, et al. Neural voice puppetry: audio⁃driven facial reenactment [C]//European conference on computer vision (ECCV). ECVA, 2020: 716–731. DOI: 10.1007/978-3-030-58517-4_42 |
| [17] | Mildenhall B, Srinivasan P P, Tancik M, et al. NeRF: representing scenes as neural radiance fields for view synthesis [J]. Communications of the ACM, 2021, 65(1): 99–106. DOI: 10.1145/3503250 |
| [18] | Shen S, Li W H, Zhu Z, et al. Learning dynamic facial radiance fields for Few⁃shot talking head synthesis [C]//European Conference on Computer Vision (ECCV). ECVA, 2022: 666–682. DOI: 10.1007/978-3-031-19775-8_39 |
| [19] | Yao S Y, Zhong R Z, Yan Y C, et al. Dfa⁃NeRF: personalized talking head generation via disentangled face attributes neural rendering [PP/OL]. arxiv (2022⁃01⁃03) [2024⁃09⁃16]. |
| [20] | Liu X, Xu Y H, Wu Q Y, et al. Semantic⁃aware implicit neural audio⁃driven video portrait generation [C]//European Conference on Computer Vision (ECCV). ECVA, 2022: 106–125. DOI: 10.1007/978-3-031-19836-6_7 |
| [21] | Ye Z H, He J Z, Jiang Z Y, et al. Geneface++: generalized and stable real⁃time audio⁃driven 3d talking face generation [PP/OL]. arxiv (2023⁃05⁃01) [2024⁃09⁃06]. |
| [22] | Yu Z T, Yin Z X, Zhou D Y, et al. Talking head generation with probabilistic audio⁃to⁃visual diffusion priors [C]//International Conference on Computer Vision (ICCV). IEEE, 2023: 7611–7621. DOI: 10.1109/ICCV51070.2023.00703 |
| [23] | Garg R, Roussos A, Agapito L. A variational approach to video registration with subspace constraints [J]. International journal of computer vision, 2013, 104(3): 286–314. DOI: 10.1007/s11263-012-0607-7 |
| [24] | Andrew A M. Multiple view geometry in computer vision [J]. Kybernetes, 2001, 30(9/10): 1333–1341. DOI: 10.1108/k.2001.30.9\_10.1333.1 |
| [25] | Kajiya J T, Von Herzen B P. Ray tracing volume densities [J]. ACM SIGGRAPH computer graphics, 1984, 18(3): 165–174. DOI: 10.1145/964965.808594 |
| [26] | Zhou H, Liu Y, Liu Z W, et al. Talking face generation by adversarially disentangled audio⁃visual representation [J]. Proceedings of the AAAI conference on artificial intelligence, 2019, 33(1): 9299–9306. DOI: 10.1609/aaai.v33i01.33019299 |
| [27] | Das D, Biswas S, Sinha S, et al. Speech⁃driven facial animation using cascaded GANs for learning of motion and texture [C]//European Conference on Computer Vision. ECVA, 2020: 408–424. DOI: 10.1007/978-3-030-58577-8_25 |
| [28] | Richard A, Zollhöfer M, Wen Y D, et al. MeshTalk: 3D face animation from speech using cross⁃modality disentanglement [C]//IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2021: 1153–1162. DOI: 10.1109/ICCV48922.2021.00121 |
| [29] | Gafni G, Thies J, Zollhofer M, et al. Dynamic neural radiance fields for monocular 4D facial avatar reconstruction [C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2021: 8645–8654. DOI: 10.1109/cvpr46437.2021.00854 |
| [30] | Hannun A, Case C, Casper J, et al. Deep Speech: scaling up end⁃to⁃end speech recognition [PP/OL]. arxiv (2014⁃12⁃19) [2024⁃09⁃06]. |
| [31] | Hong Y, Peng B, Xiao H Y, et al. HeadNeRF: a realtime NeRF⁃based parametric head model [C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022: 20342–20352. DOI: 10.1109/CVPR52688.2022.01973 |
| [32] | Ji X Y, Zhou H, Wang K, et al. EAMM: one⁃shot emotional talking face via audio⁃based emotion⁃aware motion model [C]//ACM SIGGRAPH 2022 Conference Proceedings. ACM, 2022: 1–10. DOI: 10.1145/3528233.3530745 |
| [33] | Tan S, Ji B, Pan Y. EMMN: emotional motion memory network for audio⁃driven emotional talking face generation [C]//International Conference on Computer Vision (ICCV). IEEE, 2023: 22089–22099. DOI: 10.1109/ICCV51070.2023.02024 |
| [34] | Müller T, Evans A, Schied C, et al. Instant neural graphics primitives with a multiresolution hash encoding [J]. ACM transactions on graphics, 2022, 41(4): 1–15. DOI: 10.1145/3528223.3530127 |
| [35] | Liu X, Xu Y H, Wu Q Y, et al. Semantic⁃aware implicit neural audio⁃driven video portrait generation [C]//European Conference on Computer Vision (ECCV). ECVA, 2022: 106–125. DOI: 10.1007/978-3-031-19836-6_7 |
| [36] | Zhang R, Isola P, Efros A A, et al. The unreasonable effectiveness of deep features as a perceptual metric [C]//Conference on Computer Vision and Pattern Recognition. IEEE, 2018: 586–595. DOI: 10.1109/CVPR.2018.00068 |
| [37] | Wang K, Wu Q Y, Song L S, et al. MEAD: a large⁃scale audio⁃visual dataset for emotional talking⁃face generation [C]//European conference on computer vision (ECCV). ECVA, 2020: 700–717. DOI: 10.1007/978-3-030-58589-1_42 |
| [38] | Chen L L, Li Z H, Maddox R K, et al. Lip movements generation at a glance [C]//European conference on computer vision. ECVA, 2018: 538–553. DOI: 10.1007/978-3-030-01234-2_32 |
| [39] | Chung J S, Zisserman A. Out of time: automated lip sync in the wild [EB/OL]. [2024⁃09⁃06]. . DOI: 10.1007/978-3-319-54427-4_19 |
| [40] | Lu Y X, Chai J X, Cao X. Live speech portraits: real-time photorealistic talking⁃head animation [J]. ACM transactions on graphics, 2021, 40(6): 1–17. DOI: 10.1145/3478513.3480484 |
| [41] | Martin⁃Brualla R, Radwan N, Sajjadi M S M, et al. NeRF in the wild: neural radiance fields for unconstrained photo collections [C]//Computer Vision and Pattern Recognition. IEEE, 2021: 7206–7215. DOI: 10.1109/cvpr46437.2021.00713 |
| [1] | LU Ping, FENG Daquan, SHI Wenzhe, LI Wan, LIN Jiaxin. Key Techniques and Challenges in NeRF-Based Dynamic 3D Reconstruction [J]. ZTE Communications, 2025, 23(3): 71-80. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

