ZTE Communications ›› 2025, Vol. 23 ›› Issue (4): 77-85.DOI: 10.12142/ZTECOM.202504009
• Research Papers • Previous Articles Next Articles
DONG Xiugang, ZHANG Kaijin, NONG Qingpeng, JU Minhan, TU Yaofeng( )
)
Received:2025-08-15
Online:2025-12-22
Published:2025-12-22
About author:DONG Xiugang is an AI engineer at ZTE Corporation. His work primarily focuses on the research and development of large computer vision and video understanding models. His research interests span multiple areas, including open-set object detection, semantic segmentation, video spatio-temporal localization, and general video understanding.DONG Xiugang, ZHANG Kaijin, NONG Qingpeng, JU Minhan, TU Yaofeng. Empowering Grounding DINO with MoE: An End-to-End Framework for Cross-Domain Few-Shot Object Detection[J]. ZTE Communications, 2025, 23(4): 77-85.
Add to citation manager EndNote|Ris|BibTeX
URL: https://zte.magtechjournal.com/EN/10.12142/ZTECOM.202504009
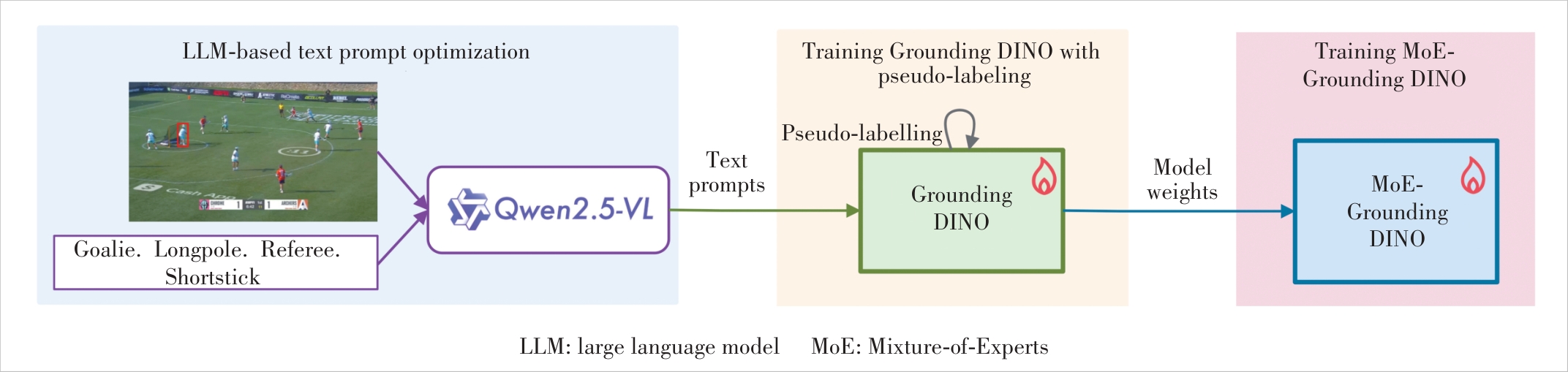
Figure 1 An illustration of the proposed end-to-end framework for cross-domain few-shot object detection (CD-FSOD)
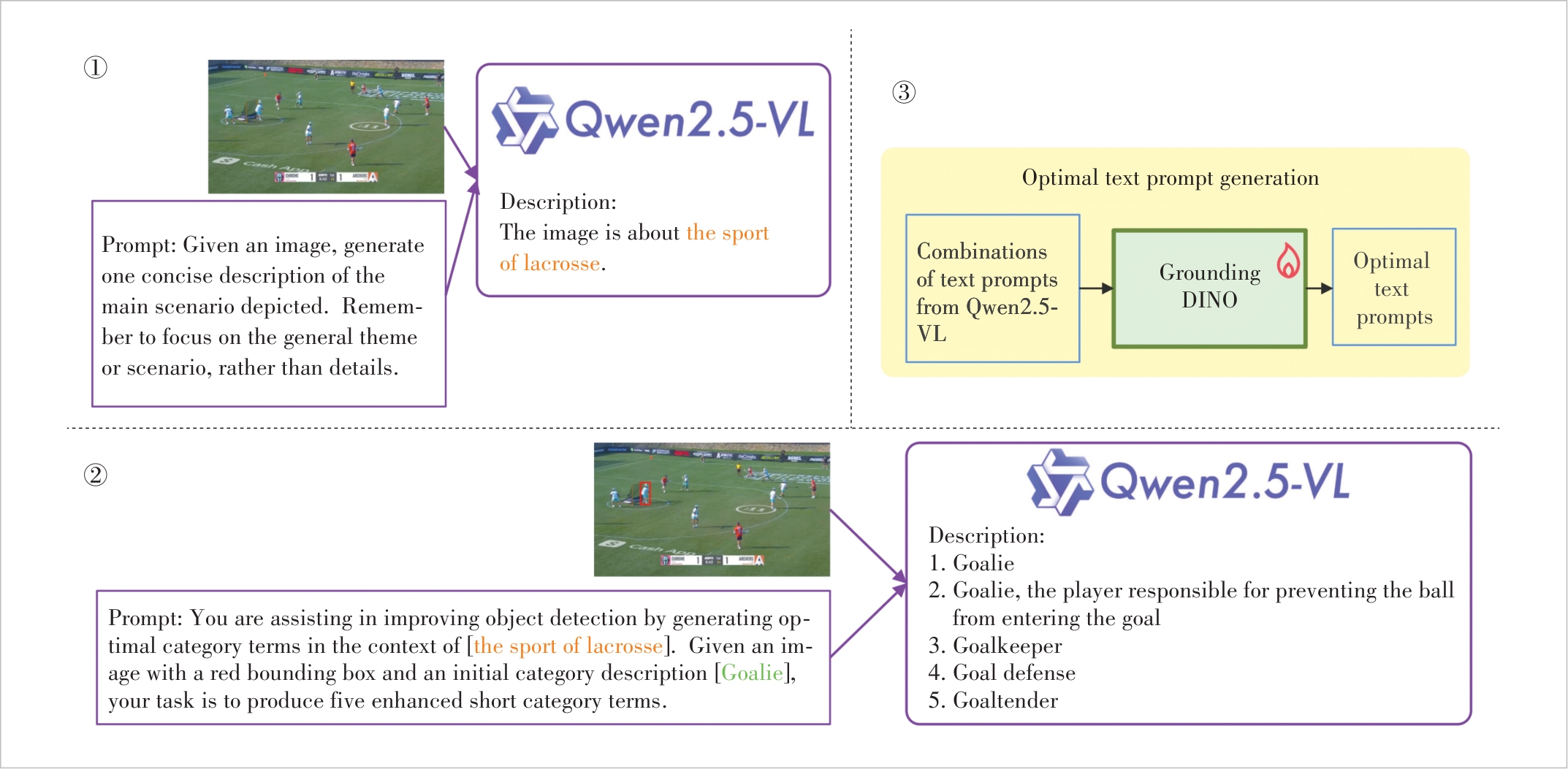
Figure 2 An example of the LLM-based text prompt optimization stage

Figure 3 An illustration of the MoE-Grounding DINO decoder layer

Figure 4 An illustration of the MoE-FFN layer

Figure 5 Illustration of the stage of fine-tuning Grounding DINO with pseudo-labeling refinement
| Framework | Aerial | Document | Flora & Fauna | Industrial | Medical | Sports | Other | All |
|---|---|---|---|---|---|---|---|---|
| TFA[ | 9.4 | 3.8 | 16.8 | 14.4 | 2.7 | 1.3 | 10.2 | 9.8 |
| Federated Detic[ | 11.6 | 14.3 | 30.8 | 24.7 | 8.9 | 17.4 | 21.0 | 20.3 |
| Grounding DINO (zero-shot) | 30.6 | 5.0 | 33.9 | 13.0 | 0.4 | 5.5 | 16.8 | 17.1 |
| Grounding DINO (sft) | 39.8 | 34.5 | 45.6 | 37.8 | 23.3 | 26.3 | 24.7 | 33.3 |
| ETS[ | 41.6 | 27.4 | 48.1 | 49.2 | 27.4 | 30.9 | 33.7 | 36.9 |
| Our framework | 49.6 | 46.3 | 55.0 | 61.3 | 42.5 | 41.2 | 45.1 | 48.7 |
Table 1 Comparison of performance of zero-shot, fine-tuned Grounding DINO with our proposed framework on Roboflow20-VL
| Framework | Aerial | Document | Flora & Fauna | Industrial | Medical | Sports | Other | All |
|---|---|---|---|---|---|---|---|---|
| TFA[ | 9.4 | 3.8 | 16.8 | 14.4 | 2.7 | 1.3 | 10.2 | 9.8 |
| Federated Detic[ | 11.6 | 14.3 | 30.8 | 24.7 | 8.9 | 17.4 | 21.0 | 20.3 |
| Grounding DINO (zero-shot) | 30.6 | 5.0 | 33.9 | 13.0 | 0.4 | 5.5 | 16.8 | 17.1 |
| Grounding DINO (sft) | 39.8 | 34.5 | 45.6 | 37.8 | 23.3 | 26.3 | 24.7 | 33.3 |
| ETS[ | 41.6 | 27.4 | 48.1 | 49.2 | 27.4 | 30.9 | 33.7 | 36.9 |
| Our framework | 49.6 | 46.3 | 55.0 | 61.3 | 42.5 | 41.2 | 45.1 | 48.7 |
| Component | Aerial | Document | Flora & Fauna | Industrial | Medical | Sports | Other | All |
|---|---|---|---|---|---|---|---|---|
| Grounding DINO (sft) | 39.8 | 34.5 | 45.6 | 37.8 | 23.3 | 26.3 | 24.7 | 33.3 |
| + text prompt optimization | 39.9 | 40.2 | 49.7 | 47.4 | 36.2 | 33.8 | 34.8 | 40.3 (+7.0) |
| + data augmentation | 48.2 | 42.5 | 53.6 | 52.0 | 37.8 | 38.1 | 40.2 | 44.6 (+4.3) |
| + pseudo-labeling | 49.6 | 44.0 | 54.6 | 56.4 | 40.2 | 39.2 | 41.6 | 46.5 (+1.9) |
| + MoE-Grounding DINO | 49.6 | 46.3 | 55.0 | 61.3 | 42.5 | 41.2 | 45.1 | 48.7 (+2.2) |
Table 2 Effectiveness of different components in our end-to-end framework on Roboflow20-VL
| Component | Aerial | Document | Flora & Fauna | Industrial | Medical | Sports | Other | All |
|---|---|---|---|---|---|---|---|---|
| Grounding DINO (sft) | 39.8 | 34.5 | 45.6 | 37.8 | 23.3 | 26.3 | 24.7 | 33.3 |
| + text prompt optimization | 39.9 | 40.2 | 49.7 | 47.4 | 36.2 | 33.8 | 34.8 | 40.3 (+7.0) |
| + data augmentation | 48.2 | 42.5 | 53.6 | 52.0 | 37.8 | 38.1 | 40.2 | 44.6 (+4.3) |
| + pseudo-labeling | 49.6 | 44.0 | 54.6 | 56.4 | 40.2 | 39.2 | 41.6 | 46.5 (+1.9) |
| + MoE-Grounding DINO | 49.6 | 46.3 | 55.0 | 61.3 | 42.5 | 41.2 | 45.1 | 48.7 (+2.2) |

Figure 6 Effect of the total number of routed experts (N) in MoE-Grounding DINO, evaluated on the Sports domain, with K fixed at 2. An N value of 0 indicates the baseline model without the MoE module
| [1] | LIU S L, ZENG Z Y, REN T H, et al. Grounding DINO: marrying DINO with grounded pre-training for open-set object detection [C]//European Conference on Computer Vision. ECCV, 2024: 38–55. DOI: 10.1007/978-3-031-72970-6_3 |
| [2] | REN T H, JIANG Q, LIU S L, et al. Grounding DINO 1.5: advance the “edge” of open-set object detection [EB/OL]. [2024-06-01]. |
| [3] | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]//European Conference on Computer Vision. ECCV, 2014: 740–755. DOI: 10.1007/978-3-319-10602-1_48 |
| [4] | MADAN A, PERI N, KONG S, et al. Revisiting few-shot object detection with vision-language models [C]//Proc. Advances in Neural Information Processing Systems 37. NeurIPS, 2024: 19547–19560. DOI: 10.52202/079017-0617 |
| [5] | FU Y Q, WANG Y, PAN Y X, et al. Cross-domain few-shot object detection via enhanced open-set object detector [C]//European Conference on Computer Vision. ECCV, 2024: 247–264. DOI: 10.1007/978-3-031-73636-0_15 |
| [6] | PAN J C, LIU Y X, HE X, et al. Enhance then search: an augmentation-search strategy with foundation models for cross-domain few-shot object detection [C]//Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2025: 1539–1547. DOI: 10.1109/CVPRW67362.2025.00143 |
| [7] | JACOBS R A, JORDAN M I, NOWLAN S J, et al. Adaptive mixtures of local experts [J]. Neural computation, 1991, 3(1): 79–87 |
| [8] | JIANG A Q, SABLAYROLLES A, ROUX A, et al. Mixtral of experts [R]. 2024 |
| [9] | LIU A, FENG B, WANG B, et al. Deepseek-v2: a strong, economical, and efficient mixture-of-experts language model [R]. 2024 |
| [10] | CAI W, JIANG J, WANG F, et al. A survey on mixture of experts [R]. 2024 |
| [11] | ROBICHEAUX P, POPOV M, MADAN A, et al. Roboflow100-vl: a multi-domain object detection benchmark for vision-language models [R]. 2025 |
| [12] | LI L H, ZHANG P C, ZHANG H T, et al. Grounded language-image pre-training [C]//Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022: 10955–10965. DOI: 10.1109/CVPR52688.2022.01069 |
| [13] | ZHONG Y W, YANG J W, ZHANG P C, et al. RegionCLIP: region-based language-image pretraining [C]//Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022: 16772–16782. DOI: 10.1109/CVPR52688.2022.01629 |
| [14] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]//International Conference on Machine Learning. PMLR, 2021: 8748–8763 |
| [15] | ZHANG H, LI F, LIU S, et al. Dino: DETR with improved denoising anchor boxes for end-to-end object detection [R]. 2022 |
| [16] | SHAO S, LI Z M, ZHANG T Y, et al. Objects365: a large-scale, high-quality dataset for object detection [C]//Proc. IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2019: 8430–8439. DOI: 10.1109/iccv.2019.00852 |
| [17] | HUDSON D A, MANNING C D. GQA: a new dataset for real-world visual reasoning and compositional question answering [C]//Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019: 6693–6702. DOI: 10.1109/CVPR.2019.00686 |
| [18] | YAN X P, CHEN Z L, XU A N, et al. Meta R-CNN: towards general solver for instance-level low-shot learning [C]//Proc. IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2019: 9577–9586. DOI: 10.1109/iccv.2019.00967 |
| [19] | HAN G X, LIM S N. Few-shot object detection with foundation models [C]//Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2024: 28608–28618. DOI: 10.1109/CVPR52733.2024.02703 |
| [20] | OQUAB M, DARCET T, MOUTAKANNI T, et al. Dinov2: learning robust visual features without supervision [R]. 2023 |
| [21] | ZHU X Z, SU W J, LU L W, et al. Deformable DETR: deformable transformers for end-to-end object detection [R]. 2021 |
| [22] | WANG X, HUANG T, GONZALEZ J, et al. Frustratingly simple few-shot object detection [C]//International Conference on Machine Learning. PMLR, 2020: 9919–9928 |
| [23] | REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]//IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137–1149. DOI: 10.1109/TPAMI.2016.2577031 |
| [24] | SINGH R, PUHL R B, DHAKAL K, et al. Few-shot adaptation of grounding DINO for agricultural domain [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2025: 5332–5342. DOI: 10.1109/CVPRW67362.2025.00530 |
| [25] | ZHOU X, GIRDHAR R, JOULIN A, et al. Detecting twenty-thousand classes using image-level supervision [C]//European Conference on Computer Vision. ECCV, 2022: 350–368. DOI: 10.1007/978-3-031-20077-9_21 |
| [26] | FEDUS W, ZOPH B, SHAZEER N. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity [J]. Journal of machine learning research, 2022, 23(120): 1–39 |
| [27] | XUE F Z, ZHENG Z A, FU Y, et al. OpenMoE: an early effort on open mixture-of-experts language models [R]. 2024 |
| [28] | BAI S, CHEN K Q, LIU X J, et al. Qwen2.5-VL technical report [R]. 2025 |
| [29] | HAN Y J, NIU J H, TU Y F. Development trends and challenges of data management systems [J]. ZTE technology journal, 2023, 27(2): 64–71. DOI: 10.12142/ZTETJ.202304012 |
| [30] | ZHAO X Y, CHEN Y C, XU S L, et al. An open and comprehensive pipeline for unified object grounding and detection [R]. 2024 |
| [31] | KUZNETSOVA A, ROM H, ALLDRIN N, et al. The open images dataset v4: unified image classification, object detection, and visual relationship detection at scale [J]. International journal of computer vision, 2020, 128(7): 1956–1981. DOI: 10.1007/s11263-020-01316-z |
| [32] | JENKINS P, SACHDEVA R, KEBE G Y, et al. Presentation and analysis of a multimodal dataset for grounded language learning [R]. 2020 |
| [33] | KAZEMZADEH S, ORDONEZ V, MATTEN M, et al. ReferItGame: referring to objects in photographs of natural scenes [C]//Proc. 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). USAACL, 2014: 787–798. DOI: 10.3115/v1/d14-1086 |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

