ZTE Communications ›› 2025, Vol. 23 ›› Issue (3): 71-80.DOI: 10.12142/ZTECOM.202503008
• Review • Previous Articles Next Articles
LU Ping1,2, FENG Daquan3, SHI Wenzhe1,2( ), LI Wan3, LIN Jiaxin3
), LI Wan3, LIN Jiaxin3
Received:2024-01-12
Online:2025-09-25
Published:2025-09-11
About author:LU Ping is the vice president and general manager of the Industrial Digitalization Solution Department of Beijing XingYun Digital Technology Co., Ltd. and the executive deputy director of the National Key Laboratory of Mobile Network and Mobile Multimedia Technology, China. His research directions include cloud computing, big data, augmented reality, and multimedia service-based technologies. He has supported and participated in major national science and technology projects. He has published multiple papers and authored two books.Supported by:LU Ping, FENG Daquan, SHI Wenzhe, LI Wan, LIN Jiaxin. Key Techniques and Challenges in NeRF-Based Dynamic 3D Reconstruction[J]. ZTE Communications, 2025, 23(3): 71-80.
Add to citation manager EndNote|Ris|BibTeX
URL: https://zte.magtechjournal.com/EN/10.12142/ZTECOM.202503008
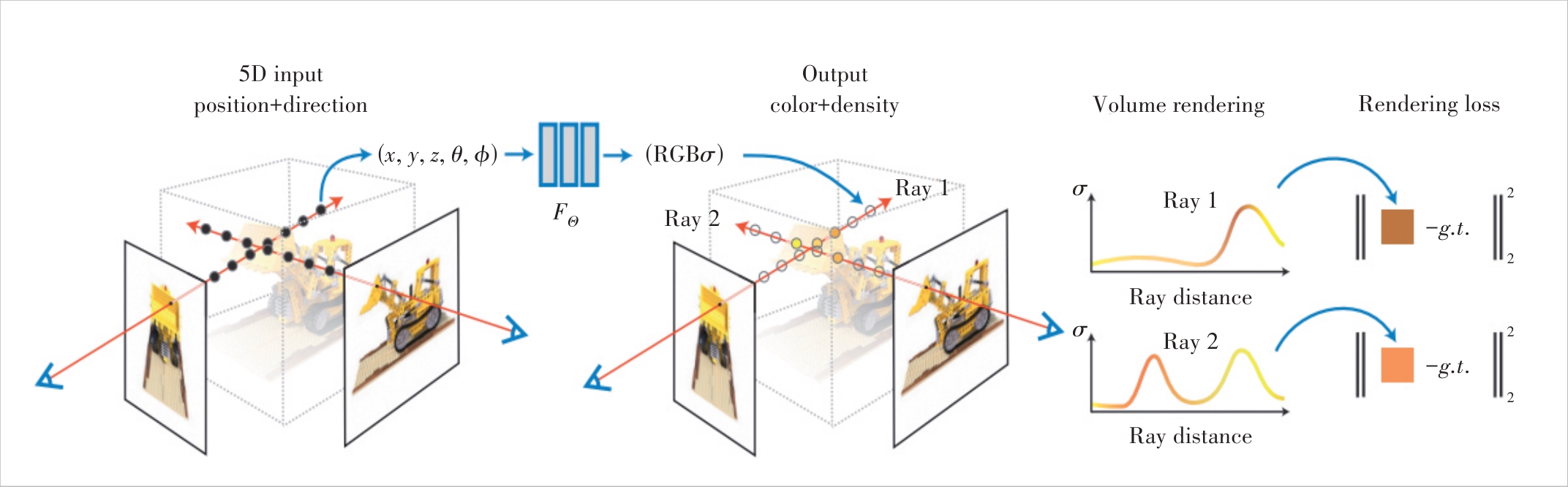
Figure 1 An overview of neural radiance field scene representation and differentiable rendering procedure
| Object | Method | Data Attribute | Required Data | 3D Representation | Year |
|---|---|---|---|---|---|
| Human-based | Neural body[ | Multi-view | I+P1+S | V | 2021 |
| Neural actors[ | Multi-view | I+P1+S | P2+VD | 2021 | |
| HVTR[ | Multi-view | P1+S | V | 2022 | |
| NDR[ | Monocular | I+P1 | P2+VD | 2022 | |
| HumanNeRF[ | Multi-view | I+P1 | P2+VD | 2022 | |
| GM-NeRF[ | Multi-view | I+P1+S | P2+VD | 2023 | |
| Scene-based | NeRFlow[ | Multi-view | I+P1 | P2+VD | 2021 |
| NeRFPlayer[ | Multi-view | I+P1 | V | 2023 | |
| DynamicNeRF[ | Monocular | I+P1+M | P2+VD | 2021 | |
| TiNeuVox[ | Multi-view | I+P1 | V | 2022 | |
| NRNeRF[ | Monocular | I+P1 | V | 2022 | |
| D-NeRF[ | Multi-view | I+P1 | P2+VD | 2021 | |
| NRNeRF[ | Monocular | I+P1 | V | 2022 | |
| Torf[ | Multi-view | I+P1 | P2+VD | 2022 | |
| Neural 3D[ | Multi-view | I+P1 | P2+VD | 2022 | |
| DynIBaR[ | Monocular | I+P1 | P2+VD | 2023 |
Table 1 An overview of the human- and scene-based reconstruction methods
| Object | Method | Data Attribute | Required Data | 3D Representation | Year |
|---|---|---|---|---|---|
| Human-based | Neural body[ | Multi-view | I+P1+S | V | 2021 |
| Neural actors[ | Multi-view | I+P1+S | P2+VD | 2021 | |
| HVTR[ | Multi-view | P1+S | V | 2022 | |
| NDR[ | Monocular | I+P1 | P2+VD | 2022 | |
| HumanNeRF[ | Multi-view | I+P1 | P2+VD | 2022 | |
| GM-NeRF[ | Multi-view | I+P1+S | P2+VD | 2023 | |
| Scene-based | NeRFlow[ | Multi-view | I+P1 | P2+VD | 2021 |
| NeRFPlayer[ | Multi-view | I+P1 | V | 2023 | |
| DynamicNeRF[ | Monocular | I+P1+M | P2+VD | 2021 | |
| TiNeuVox[ | Multi-view | I+P1 | V | 2022 | |
| NRNeRF[ | Monocular | I+P1 | V | 2022 | |
| D-NeRF[ | Multi-view | I+P1 | P2+VD | 2021 | |
| NRNeRF[ | Monocular | I+P1 | V | 2022 | |
| Torf[ | Multi-view | I+P1 | P2+VD | 2022 | |
| Neural 3D[ | Multi-view | I+P1 | P2+VD | 2022 | |
| DynIBaR[ | Monocular | I+P1 | P2+VD | 2023 |
| Name | Object | Cases | Cameras | Resolution | Year |
|---|---|---|---|---|---|
| DNA-Rendering | Human-based | 439 | 60 | 4K | 2023 |
| ZJU_MoCap | Human-based | 9 | 23 | 1K | 2021 |
| ENeRF-Outdorr | Scene-based | 8 | 18 | 4K | 2022 |
| NVIDIA | Scene-based | 12 | 4 scenes with monocular; 8 scenes with 12 cameras | 960×540 | 2020 |
Table 2 Information on commonly used datasets for dynamic 3D reconstruction
| Name | Object | Cases | Cameras | Resolution | Year |
|---|---|---|---|---|---|
| DNA-Rendering | Human-based | 439 | 60 | 4K | 2023 |
| ZJU_MoCap | Human-based | 9 | 23 | 1K | 2021 |
| ENeRF-Outdorr | Scene-based | 8 | 18 | 4K | 2022 |
| NVIDIA | Scene-based | 12 | 4 scenes with monocular; 8 scenes with 12 cameras | 960×540 | 2020 |

Figure 2 A novel viewpoint synthesis framework based on dynamic and static distributions
| [1] | GONZÁLEZ IZARD S, SÁNCHEZ TORRES R, ALONSO PLAZA Ó, et al. Nextmed: automatic imaging segmentation, 3D reconstruction, and 3D model visualization platform using augmented and virtual reality [J]. Sensors, 2020, 20(10): 2962. DOI: 10.3390/s20102962 |
| [2] | LI H M. 3D indoor scene reconstruction and layout based on virtual reality technology and few-shot learning [EB/OL]. [2024-01-02]. |
| [3] | TANG F L, WU Y H, HOU X H, et al. 3D mapping and 6D pose computation for real time augmented reality on cylindrical objects [J]. IEEE transactions on circuits and systems for video technology, 2020, 30(9): 2887–2899. DOI: 10.1109/TCSVT.2019.2950449 |
| [4] | SAMAVATI T, SORYANI M. Deep learning-based 3D reconstruction: a survey [J]. Artificial intelligence review, 2023, 56(9): 9175–9219. DOI: 10.1007/s10462-023-10399-2 |
| [5] | PALAZZOLO E, BEHLEY J, LOTTES P, et al. ReFusion: 3D reconstruction in dynamic environments for RGB-D cameras exploiting residuals [C]//International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019: 7855–7862. DOI: 10.1109/IROS40897.2019.8967590 |
| [6] | STIER N, ANGLES B, YANG L, et al. LivePose: online 3D reconstruction from monocular video with dynamic camera poses [EB/OL]. [2024-01-02]. |
| [7] | NOVOTNY D, ROCCO I, SINHA S, et al. KeyTr: keypoint transporter for 3D reconstruction of deformable objects in videos [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022: 5585–5594. DOI: 10.1109/CVPR52688.2022.00551 |
| [8] | CHEN X T, SRA M. IntoTheVideos: exploration of dynamic 3D space reconstruction from single sports videos [C]//The 34th Annual ACM Symposium on User Interface Software and Technology. ACM, 2021: 14–16. DOI: 10.1145/3474349.3480215 |
| [9] | WANG B, JIN Y, CHEN Y X, et al. Gaze tracking 3D reconstruction of object with large-scale motion [J]. IEEE transactions on instrumentation and measurement, 2023, 72: 7002612. DOI: 10.1109/TIM.2023.3251419 |
| [10] | REMONDINO F, KARAMI A, YAN Z Y, et al. A critical analysis of NeRF-based 3D reconstruction [J]. Remote sensing, 2023, 15(14): 3585. DOI: 10.3390/rs15143585 |
| [11] | CHEN H S, GU J T, CHEN A P, et al. Single-stage diffusion nerf: a unified approach to 3D generation and reconstruction [EB/OL]. (2023-04-13) [2024-01-02]. |
| [12] | XU H Y, ALLDIECK T, SMINCHISESCU C. H-nerf: neural radiance fields for rendering and temporal reconstruction of humans in motion [EB/OL]. (2021-10-26) [2024-01-02]. |
| [13] | XU J K, PENG L, CHEN H R, et al. MonoNeRD: NeRF-like representations for monocular 3D object detection [C]//International Conference on Computer Vision. IEEE, 2023: 6791–6801. DOI: 10.1109/ICCV51070.2023.00627 |
| [14] | LI S X, LI C J, ZHU W B, et al. Instant-3D: instant neural radiance field training towards on-device AR/VR 3D reconstruction [C]//The 50th Annual International Symposium on Computer Architecture. ACM, 2023: 1–13. DOI: 10.1145/3579371.3589115 |
| [15] | KIRSCHSTEIN T, QIAN S, GIEBENHAIN S, et al. NeRSemble: multi-view radiance field reconstruction of human heads [EB/OL]. (2023-05-04) [2024-01-02]. |
| [16] | CHEN J, YI W, MA L, et al. GM-NeRF: learning generalizable model-based neural radiance fields from multi-view images [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2023: 20648–20658 |
| [17] | GAO H, LI R, TULSIANI S, et al. Monocular dynamic view synthesis: a reality check [J]. Advances in neural information processing systems, 2022, 35: 33768–33780 |
| [18] | LI T Y, SLAVCHEVA M, ZOLLHOEFER M, et al. Neural 3D video synthesis from multi-view video [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022: 5511–5521. DOI: 10.1109/CVPR52688.2022.00544 |
| [19] | ZHANG J Z, LUO H M, YANG H D, et al. NeuralDome: a neural modeling pipeline on multi-view human-object interactions [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023: 8834–8845. DOI: 10.1109/CVPR52729.2023.00853 |
| [20] | WEI Y, LIU S H, RAO Y M, et al. NerfingMVS: guided optimization of neural radiance fields for indoor multi-view stereo [C]//Proceedings of IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2021: 5590–5599. DOI: 10.1109/ICCV48922.2021.00556 |
| [21] | DENG F W, HUANG S J. High-precision 3D structure optical measurement technology for 5G power modules [J]. ZTE technology journal, 2024, 30(5): 75–80. DOI: 10.12142/ZTETJ.202405011 |
| [22] | FENG D Q, ZHANG S L, LYU X Y, et al. Metaverse: concept, architecture, and suggestions [J]. ZTE technology journal, 2024, 30(S1): 3–15. DOI: 10.12142/ZTETJ.2024S1002 |
| [23] | MESCHEDER L, OECHSLE M, NIEMEYER M, et al. Occupancy networks: learning 3D reconstruction in function space [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019: 4455–4465. DOI: 10.1109/CVPR.2019.00459 |
| [24] | CHEN Z Q, ZHANG H. Learning implicit fields for generative shape modeling [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019: 5932–5941. DOI: 10.1109/cvpr.2019.00609 |
| [25] | PARK J J, FLORENCE P, STRAUB J, et al. Deepsdf: learning continuous signed distance functions for shape representation [C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. IEEE, 2019: 165–174 |
| [26] | SAITO S, HUANG Z, NATSUME R, et al. PIFu: pixel-aligned implicit function for high-resolution clothed human digitization [C]//Proceedings of IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2019: 2304–2314. DOI: 10.1109/ICCV.2019.00239 |
| [27] | NIEMEYER M, MESCHEDER L, OECHSLE M, et al. Differentiable volumetric rendering: learning implicit 3D representations without 3D supervision [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020: 3501–3512. DOI: 10.1109/cvpr42600.2020.00356 |
| [28] | SITZMANN V, ZOLLHÖFER M, WETZSTEIN G. Scene representation networks: continuous 3D-structure-aware neural scene representations [C]//The 33rd International Conference on Neural Information Processing Systems. ACM, 2019: 1121–1132 |
| [29] | MILDENHALL B, SRINIVASAN P P, TANCIK M, et al. NeRF: representing scenes as neural radiance fields for view synthesis [EB/OL]. (2020-03-19) [2024-01-02]. |
| [30] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]//The 31st International Conference on Neural Information Processing System. ACM, 2017: 6000–6010 |
| [31] | TANCIK M, SRINIVASAN P, MILDENHALL B, et al. Fourier features let networks learn high frequency functions in low dimensional domains [C]//The 34th International Conference on Neural Information Processing Systems. ACM, 2020: 7537–7547 |
| [32] | YU A, YE V, TANCIK M, et al. PixelNeRF: neural radiance fields from one or few images [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2021: 4576–4585. DOI: 10.1109/cvpr46437.2021.00455 |
| [33] | ZHANG K, RIEGLER G, SNAVELY N, et al. Nerf++: analyzing and improving neural radiance fields [EB/OL]. (2020-10-15) [2024-01-02]. |
| [34] | WANG Z, WU S, XIE W, et al. NeRF--: neural radiance fields without known camera parameters [EB/OL]. (2021-02-14) [2024-01-02]. |
| [35] | BARRON J T, MILDENHALL B, TANCIK M, et al. Mip-nerf: a multiscale representation for anti-aliasing neural radiance fields [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. IEEE, 2021: 5855–5864. DOI: 10.1109/ICCV48922.2021.00580 |
| [36] | PENG S, ZHANG Y, XU Y, et al. Neural body: implicit neural representations with structured latent codes for novel view synthesis of dynamic humans [J]. IEEE Transactions on pattern analysis and machine intelligence. 2021: 9054–9063 |
| [37] | LIU L J, HABERMANN M, RUDNEV V, et al. Neural actor [J]. ACM transactions on graphics, 2021, 40(6): 1–16. DOI: 10.1145/3478513.3480528 |
| [38] | HU T, YU T, ZHENG Z R, et al. HVTR: hybrid volumetric-textural rendering for human avatars [C]//International Conference on 3D Vision (3DV). IEEE, 2022: 197–208. DOI: 10.1109/3DV57658.2022.00032 |
| [39] | CAI H, FENG W, FENG X, et al. Neural surface reconstruction of dynamic scenes with monocular RGB-D camera [J]. Advances in neural information processing systems, 2022, 35: 967–981 |
| [40] | WENG C, CURLESS B, SRINIVASAN P P, et al. HumanNeRF: free-viewpoint rendering of moving people from monocular video [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022: 16189–16199. DOI: 10.1109/CVPR52688.2022.01573 |
| [41] | CHEN J C, YI W T, MA L Q, et al. GM-NeRF: learning generalizable model-based neural radiance fields from multi-view images [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023: 20648–20658. DOI: 10.1109/CVPR52729.2023.01978 |
| [42] | NOGUCHI A, SUN X, LIN S, et al. Neural articulated radiance field [C]//Proceedings of IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2021: 5742–5752. DOI: 10.1109/ICCV48922.2021.00571 |
| [43] | SU S Y, YU F, ZOLLHOEFER M, et al. A-nerf: surface-free human 3D pose refinement via neural rendering [EB/OL]. (2021-10-29) [2024-01-02]. |
| [44] | PENG S, DONG J, WANG Q, et al. Animatable neural radiance fields for human body modeling [EB/OL]. (2021-10-07) [2024-01-02]. |
| [45] | DU Y L, ZHANG Y N, YU H X, et al. Neural radiance flow for 4D view synthesis and video processing [C]//Proceedings of IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2021: 14304–14314. DOI: 10.1109/ICCV48922.2021.01406 |
| [46] | SONG L C, CHEN A P, LI Z, et al. NeRFPlayer: a streamable dynamic scene representation with decomposed neural radiance fields [J]. IEEE transactions on visualization and computer graphics, 2023, 29(5): 2732–2742. DOI: 10.1109/TVCG.2023.3247082 |
| [47] | GAO C, SARAF A, KOPF J, et al. Dynamic view synthesis from dynamic monocular video [C]//Proceedings of IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2021: 5692–5701. DOI: 10.1109/ICCV48922.2021.00566 |
| [48] | FANG J M, YI T R, WANG X G, et al. Fast dynamic radiance fields with time-aware neural voxels [C]//Proceedings of SIGGRAPH Asia 2022 Conference Papers. ACM, 2022: 1–9. DOI: 10.1145/3550469.3555383 |
| [49] | ABOU-CHAKRA J, DAYOUB F, SÜNDERHAUF N. Particlenerf: particle based encoding for online neural radiance fields in dynamic scenes [EB/OL]. (2023-03-24) [2024-01-02]. |
| [50] | PUMAROLA A, CORONA E, PONS-MOLL G, et al. D-NeRF: neural radiance fields for dynamic scenes [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2021: 10313–10322. DOI: 10.1109/cvpr46437.2021.01018 |
| [51] | TRETSCHK E, TEWARI A, GOLYANIK V, et al. Non-rigid neural radiance fields: reconstruction and novel view synthesis of a dynamic scene from monocular video [EB/OL]. (2020-12-22) [2024-01-02]. |
| [52] | ATTAL B, LAIDLAW E, GOKASLAN A, et al. Törf: time-of-flight radiance fields for dynamic scene view synthesis [C]//The 35th International Conference on Neural Information Processing Systems. ACM, 2021: 26289–26301 |
| [53] | LI T, SLAVCHEVA M, ZOLLHOEFER M, et al. Neural 3D video synthesis [EB/OL]. (2021-03-03) [2024-01-02]. |
| [54] | LI Z Q, WANG Q Q, COLE F, et al. DynIBaR: neural dynamic image-based rendering [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023: 4273–4284. DOI: 10.1109/CVPR52729.2023.00416 |
| [55] | CHENG W, CHEN R X, FAN S M, et al. DNA-rendering: a diverse neural actor repository for high-fidelity human-centric rendering [C]//Proceedings of IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2023: 19925–19936. DOI: 10.1109/ICCV51070.2023.01829 |
| [56] | LIN H T, PENG S D, XU Z, et al. Efficient neural radiance fields for interactive free-viewpoint video [C]//Proceedings of SIGGRAPH Asia 2022 Conference Papers. ACM, 2022: 1–9. DOI: 10.1145/3550469.3555376 |
| [57] | YOON J S, KIM K, GALLO O, et al. Novel view synthesis of dynamic scenes with globally coherent depths from a monocular camera [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2020: 5336–5345 |
| [58] | WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity [J]. IEEE transactions on image processing, 2004, 13(4): 600–612. DOI: 10.1109/tip.2003.819861 |
| [59] | ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric [C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2018: 586–595. DOI: 10.1109/CVPR.2018.00068 |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

