ZTE Communications ›› 2025, Vol. 23 ›› Issue (1): 30-44.DOI: 10.12142/ZTECOM.202501005
• Special Topic • Previous Articles Next Articles
REN Tianqi1, LI Rongpeng1( ), ZHAO Mingmin1, CHEN Xianfu2, LIU Guangyi3, YANG Yang4, ZHAO Zhifeng1,5, ZHANG Honggang6
), ZHAO Mingmin1, CHEN Xianfu2, LIU Guangyi3, YANG Yang4, ZHAO Zhifeng1,5, ZHANG Honggang6
Received:2025-01-02
Online:2025-03-25
Published:2025-03-25
About author:REN Tianqi received his BE degree in electronic science and technology from Zhejiang University, China in 2024. He is currently pursuing his ME degree in electronic and information engineering with Zhejiang University. His research interests include application of large language models in communication scenarios and semantic communications.Supported by:REN Tianqi, LI Rongpeng, ZHAO Mingmin, CHEN Xianfu, LIU Guangyi, YANG Yang, ZHAO Zhifeng, ZHANG Honggang. Separate Source Channel Coding Is Still What You Need: An LLM-Based Rethinking[J]. ZTE Communications, 2025, 23(1): 30-44.
Add to citation manager EndNote|Ris|BibTeX
URL: https://zte.magtechjournal.com/EN/10.12142/ZTECOM.202501005
| Notation | Definition |
|---|---|
| The transmitted text sequence and the recovered text sequenceat the receiver side | |
| The transmitted token sequence and the recovered token sequence at the receiver side | |
| The source code and the channel code (error correction code) | |
| The source distribution and the predicted probability distribution via LLM | |
| The dictionary of source coder, the i-th character in the dictionary, and the vocabulary of the dictionary | |
| The probability interval in step k of source coding and its corresponding lower and upper bounds | |
| The message encoded by the source coder and the received (and channel decoded) message | |
| The probability interval, determined by the codeword, in a decimal form | |
| The codeword length and message length of error correction code | |
| The generator matrix and the parity check matrix | |
| The transmitted codeword encoded by the channel coder and its binary and sign form | |
| The soft approximation of codeword and its binary form | |
| The Gaussian distribution and the standard deviation of noise | |
| The channel fading coefficient | |
| The additive Gaussian noise, as well as its corresponding multiplicative noise and the prediction result by ECCT | |
| The noisy codeword, its binary form, and the result of pre-processing noisy codeword | |
| The syndrome of codes defined in ECCT | |
| The decoding function of ECCT | |
| The learnable embedding matrix for high-dimensional mapping | |
| The code-aware self-attention mask |
Table 1 Major notations used in this paper
| Notation | Definition |
|---|---|
| The transmitted text sequence and the recovered text sequenceat the receiver side | |
| The transmitted token sequence and the recovered token sequence at the receiver side | |
| The source code and the channel code (error correction code) | |
| The source distribution and the predicted probability distribution via LLM | |
| The dictionary of source coder, the i-th character in the dictionary, and the vocabulary of the dictionary | |
| The probability interval in step k of source coding and its corresponding lower and upper bounds | |
| The message encoded by the source coder and the received (and channel decoded) message | |
| The probability interval, determined by the codeword, in a decimal form | |
| The codeword length and message length of error correction code | |
| The generator matrix and the parity check matrix | |
| The transmitted codeword encoded by the channel coder and its binary and sign form | |
| The soft approximation of codeword and its binary form | |
| The Gaussian distribution and the standard deviation of noise | |
| The channel fading coefficient | |
| The additive Gaussian noise, as well as its corresponding multiplicative noise and the prediction result by ECCT | |
| The noisy codeword, its binary form, and the result of pre-processing noisy codeword | |
| The syndrome of codes defined in ECCT | |
| The decoding function of ECCT | |
| The learnable embedding matrix for high-dimensional mapping | |
| The code-aware self-attention mask |
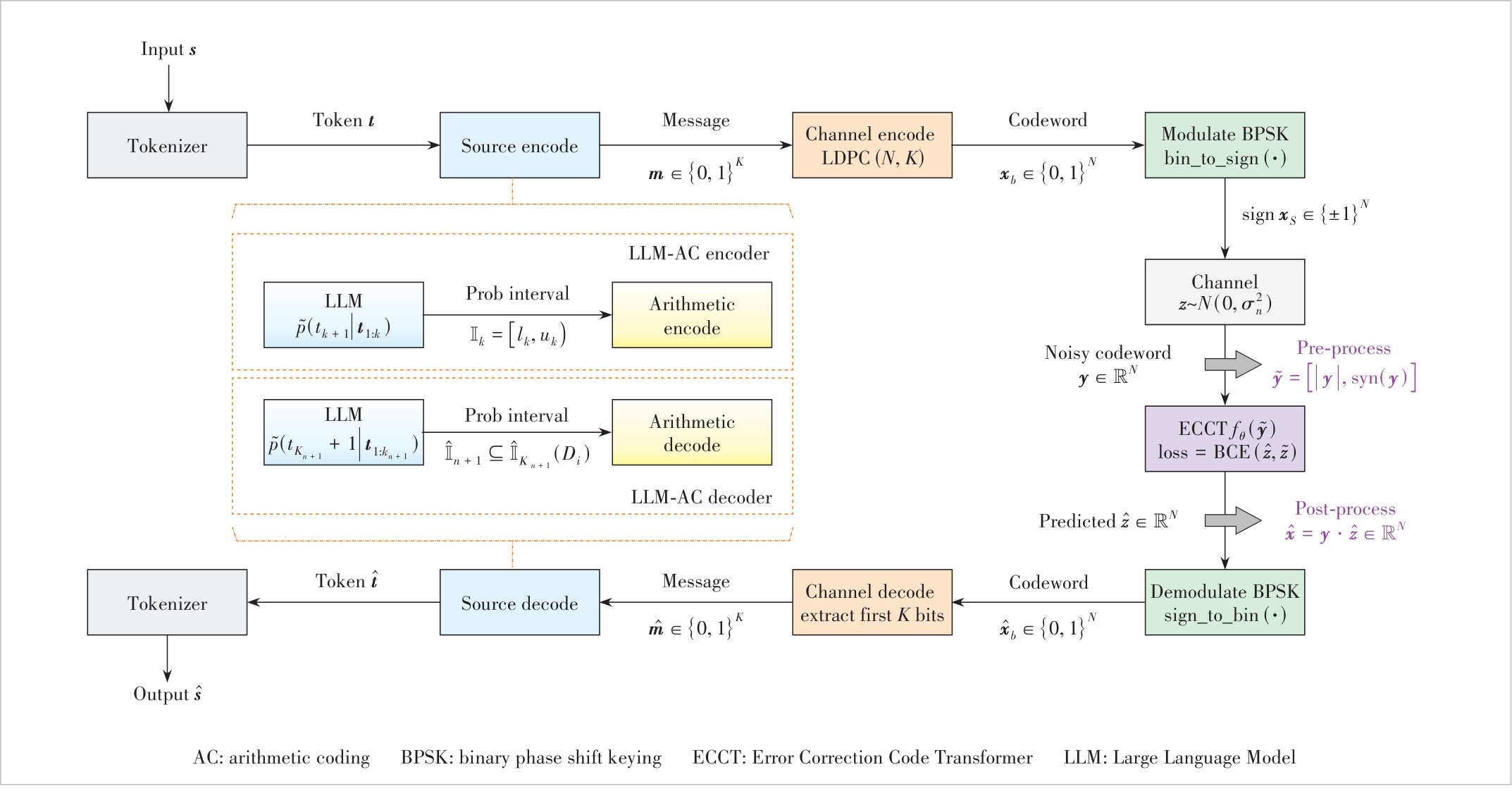
Figure 1 Framework of LLM-based and ECCT-complemented SSCC system
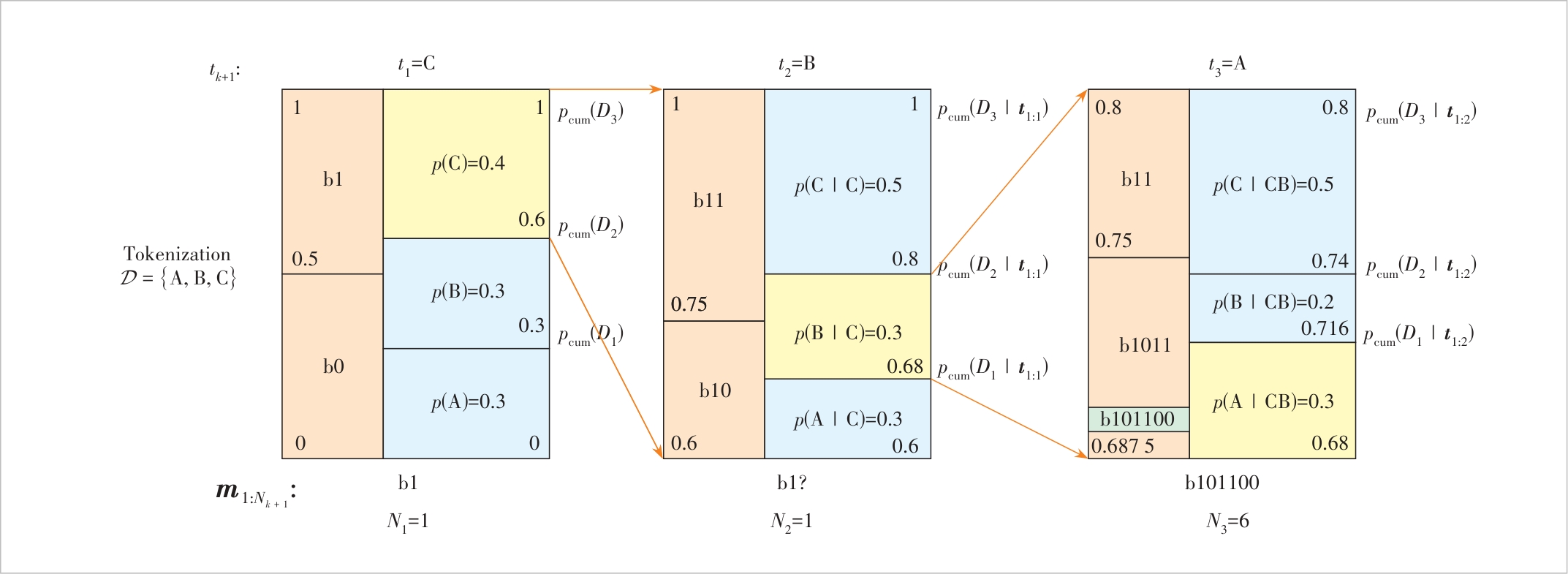
Figure 2 An example of arithmetic coding
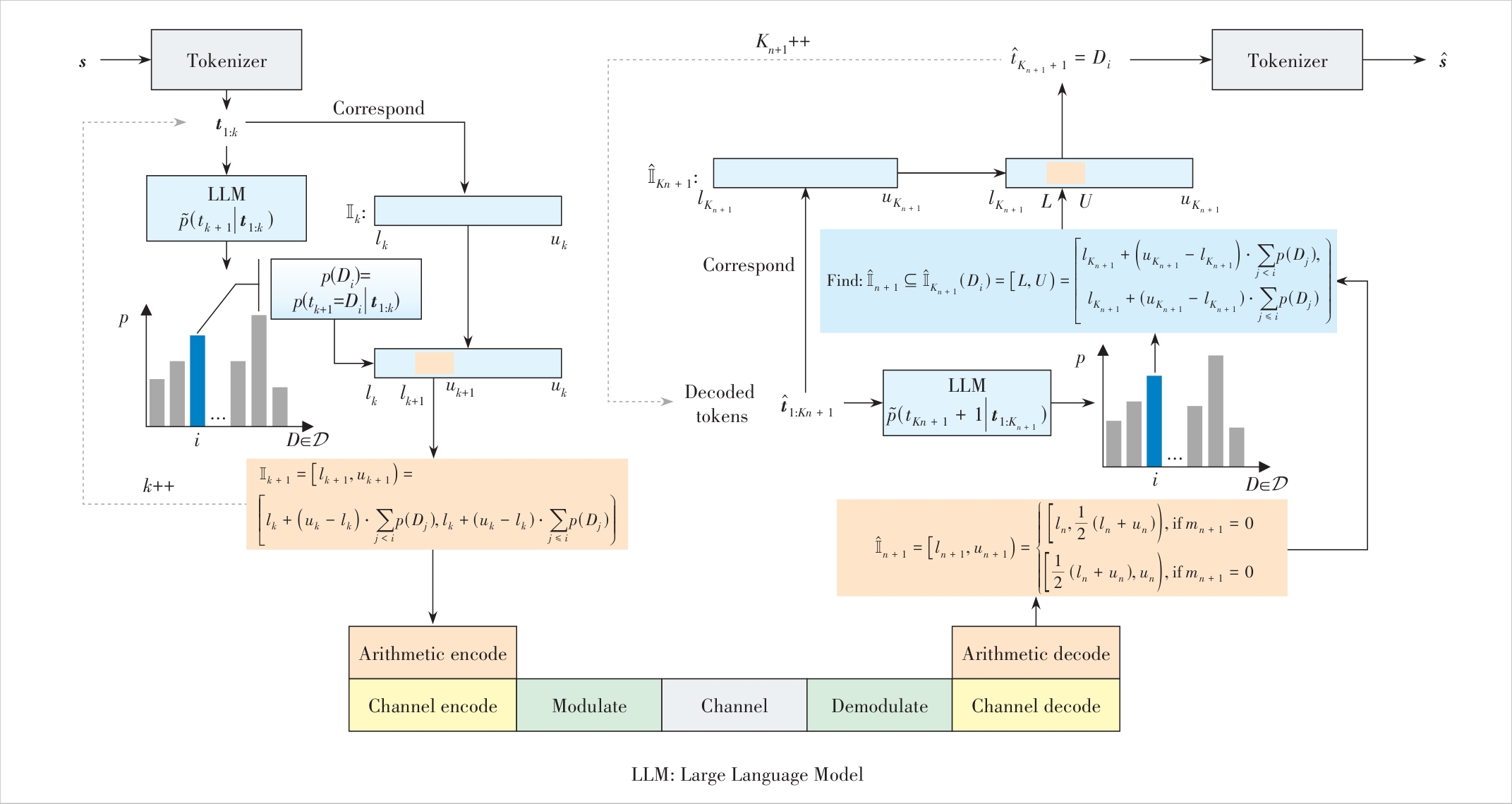
Figure 3 LLM-based arithmetic encoding and decoding

Figure 4 ECCT architecture
| Model | Hyperparameter | Value |
|---|---|---|
| ECCT | Learning rate | |
| Batch size | ||
| Number of decoder layers | ||
| Dimension of embedding | ||
| Number of attention heads | ||
| DeepSC | Learning rate | |
| Batch size | ||
| Number of encoder/decoder layers | ||
| Dimension of embedding | ||
| Dimension of FFN | ||
| Number of attention heads | ||
| UT | Learning rate | |
| Batch size | ||
| Number of encoder/decoder layers | ||
| Dimension of embedding | ||
| Dimension of FFN | ||
| Number of attention heads |
Table 2 Mainly used hyperparameters in the experiments
| Model | Hyperparameter | Value |
|---|---|---|
| ECCT | Learning rate | |
| Batch size | ||
| Number of decoder layers | ||
| Dimension of embedding | ||
| Number of attention heads | ||
| DeepSC | Learning rate | |
| Batch size | ||
| Number of encoder/decoder layers | ||
| Dimension of embedding | ||
| Dimension of FFN | ||
| Number of attention heads | ||
| UT | Learning rate | |
| Batch size | ||
| Number of encoder/decoder layers | ||
| Dimension of embedding | ||
| Dimension of FFN | ||
| Number of attention heads |

Figure 5 BLEU and similarity scores versus SNRunified are evaluated for the same number of transmitted symbols. The proposed LLM-based SSCC is compared with Huffman coding with LDPC49,?24 in BPSK, DeepSC, UT, and UT with quantization under the AWGN channel
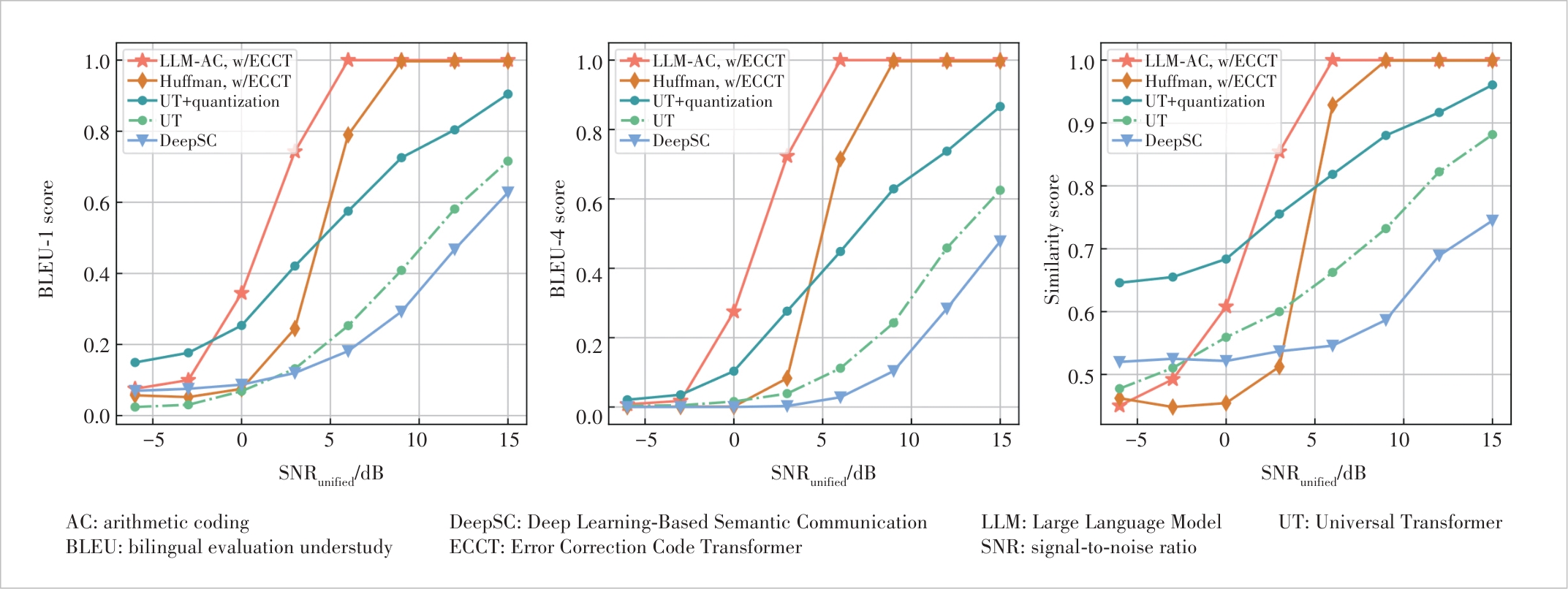
Figure 6 BLEU and similarity scores versus SNRunified are evaluated for the same number of transmitted symbols. The proposed LLM-based SSCC is compared with Huffman coding with LDPC49,?24 in BPSK; DeepSC, UT, and UT with quantization trained under the Rayleigh fading channel
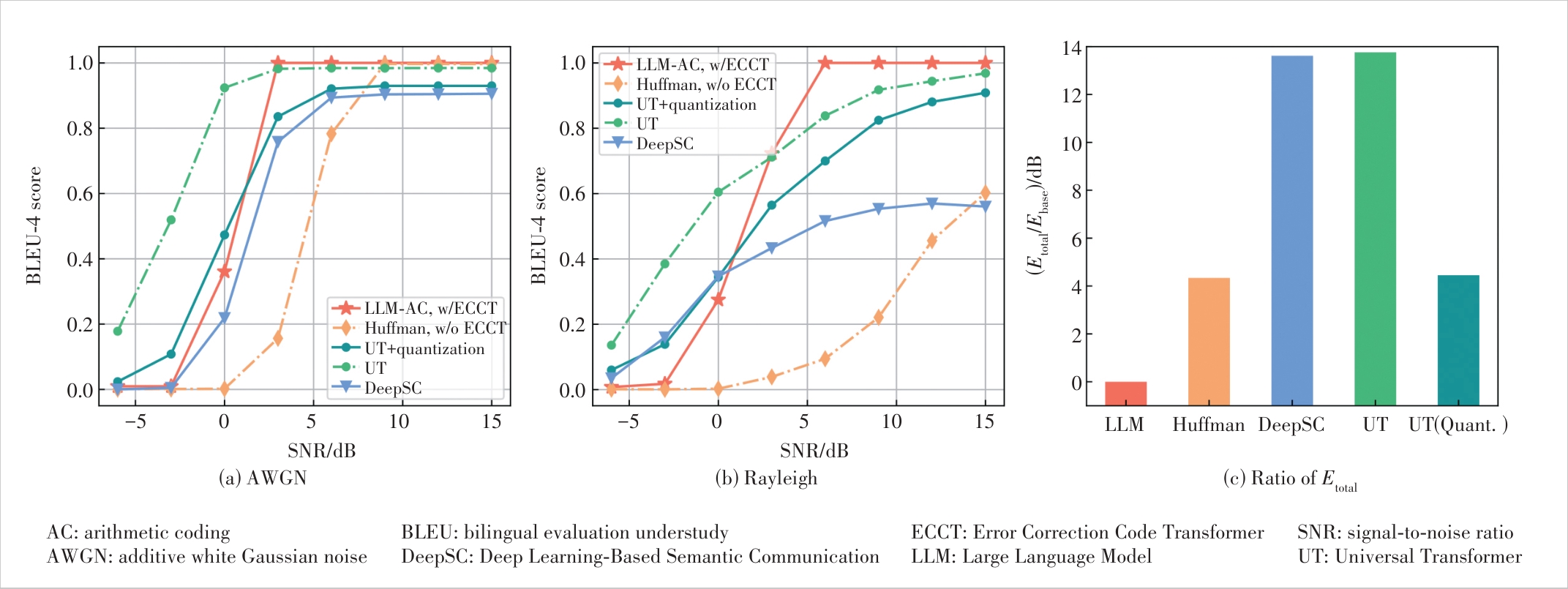
Figure 7 BLEU-4 score versus SNR is evaluated for the same number of transmitted symbols. The proposed LLM-based SSCC is compared with Huffman coding with LDPC49,?24 in BPSK (without ECCT), DeepSC, UT, and UT with quantization trained under (a) AWGN and (b) Rayleigh fading channels; (c) shows the ratio of Etotal among different systems

Figure 8 BLEU-4 score versus SNRunified for the same number of transmitted symbols, with different code rates using LDPC49,?24?/LDPC49,?30/LDPC49,?36 in BPSK, compared with the situations removing ECCT, under (a) AWGN and (b) Rayleigh fading channels

Figure 9 BLEU and similarity scores of models versus SNRunified, with different parameter scales (GPT2, GPT2-medium, GPT2-large, GPT2-XL), using LDPC121,?110 as the error correction code
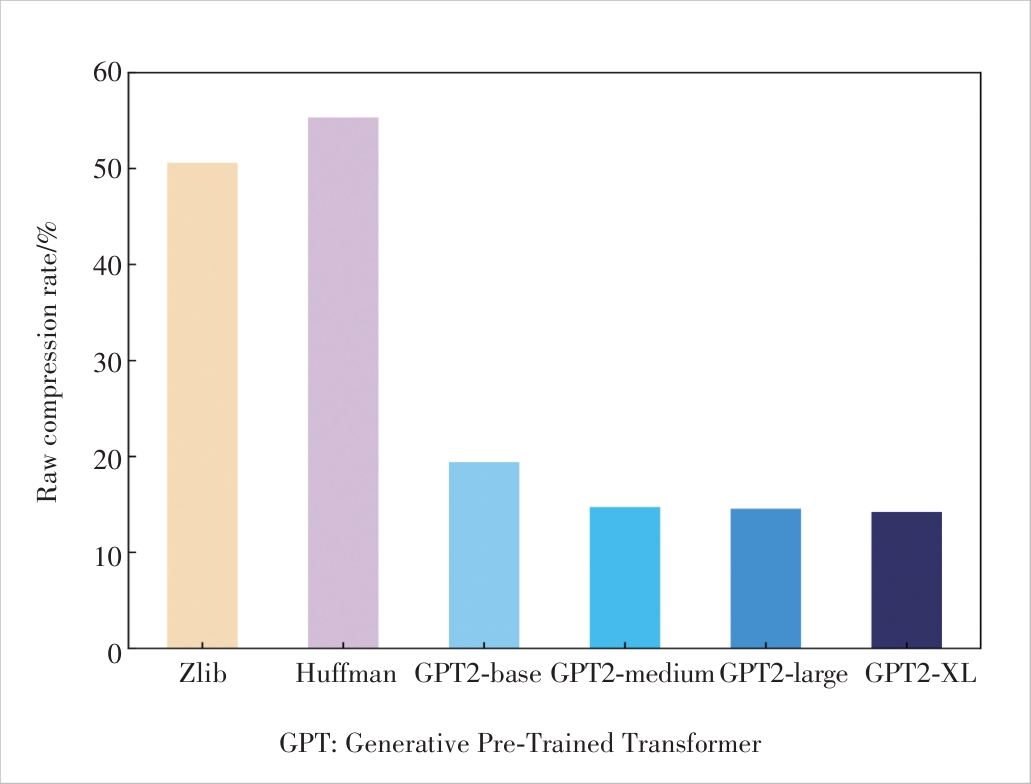
Figure 10 Compression rate comparison between traditional methods (Zlib and Huffman coding) and LLM-AC
| Block size | Similarity | BLEU-1 | BLEU-4 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| -6 | 0 | 6 | -6 | 0 | 6 | -6 | 0 | 6 | |
| 16 | |||||||||
| 32 | |||||||||
| 64 | |||||||||
| 128 | |||||||||
Table 3 Influence of token block sizes on system performance during LLM-based arithmetic source encoding for SNR={-6, 0, 6}
| Block size | Similarity | BLEU-1 | BLEU-4 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| -6 | 0 | 6 | -6 | 0 | 6 | -6 | 0 | 6 | |
| 16 | |||||||||
| 32 | |||||||||
| 64 | |||||||||
| 128 | |||||||||
| 1 | LU Z L, LI R P, LU K. Semantics-empowered communication: a tutorial-cum-survey [J]. IEEE communications surveys and tutorials, 2024, 26(1): 41–79. DOI: 10.1109/COMST.2023.333334 |
| 2 | KURKA D B, GÜNDÜZ D. DeepJSCC-f: deep joint source-channel coding of images with feedback [J]. IEEE journal on selected areas in information theory, 2020, 1(1): 178–193. DOI: 10.1109/JSAIT.2020.2987203 |
| 3 | BAO Z C, LIANG H T, DONG C, et al. MDVSC: wireless model division video semantic communication for 6G [C]//Proc. IEEE Globecom Workshops (GC Wkshps). IEEE, 2023: 1572–1578. DOI: 10.1109/GCWkshps58843.2023.10464666 |
| 4 | JIA Y J, HUANG Z, LUO K, et al. Lightweight joint source-channel coding for semantic communications [J]. IEEE communications letters, 2023, 27(12): 3161–3165. DOI: 10.1109/LCOMM.2023.3329533 |
| 5 | LIU S C, GAO Z, CHEN G J, et al. Transformer-based joint source channel coding for textual semantic communication [C]//Proc. IEEE/CIC International Conference on Communications in China (ICCC). IEEE, 2023: 1–6. DOI: 10.1109/ICCC57788.2023.10233424 |
| 6 | LIU X Y, HUANG Z, ZHANG Y L, et al. CNN and attention-based joint source channel coding for semantic communications in WSNs [J]. Sensors, 2024, 24(3): 957. DOI: 10.3390/s24030957 |
| 7 | LU Z L, LI R P, LEI M, et al. Self-critical alternate learning based semantic broadcast communication [J]. IEEE transactions on communications, 2024: 1. DOI: 10.1109/tcomm.2024.3487513 |
| 8 | TONG W J, LIU F F, SUN Z F, et al. Image semantic communications: an extended rate-distortion theory based scheme [C]//Proc. IEEE Globecom Workshops (GC Wkshps). IEEE, 2022: 1723–1728. DOI: 10.1109/GCWkshps56602.2022.10008733 |
| 9 | TONG S Y, YU X X, LI R P, et al. Alternate learning based sparse semantic communications for visual transmission [C]//Proc. 34th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC). IEEE, 2023. DOI: 10.1109/pimrc56721.2023.10293971 |
| 10 | TONG S Y, YU X X, LI R P, et al. Alternate learning-based SNR-adaptive sparse semantic visual transmission [J]. IEEE transactions on wireless communications, 2025, 24: 1737–1752. DOI: 10.1109/TWC.2024.3512652 |
| 11 | WANG J, WANG S X, DAI J C, et al. Perceptual learned source-channel coding for high-fidelity image semantic transmission [C]//Proc. IEEE Global Communications Conference. IEEE, 2022: 3959–3964. DOI: 10.1109/GLOBECOM48099.2022.10001359 |
| 12 | XIE H Q, QIN Z J, LI G Y, et al. Deep learning enabled semantic communication systems [J]. IEEE transactions on signal processing, 2021, 69: 2663–2675. DOI: 10.1109/tsp.2021.3071210 |
| 13 | ZHANG W Y, BAI K Y, ZEADALLY S, et al. DeepMA: end-to-end deep multiple access for wireless image transmission in semantic communication [J]. IEEE transactions on cognitive communications and networking, 10(2): 387–402. DOI: 10.1109/tccn.2023.3326302 |
| 14 | ZHOU Q Y, LI R P, ZHAO Z F, et al. Semantic communication with adaptive universal transformer [J]. IEEE wireless communications letters, 2022, 11(3): 453–457. DOI: 10.1109/LWC.2021.3132067 |
| 15 | GOYAL M, TATWAWADI K, CHANDAK S, et al. DeepZip: lossless data compression using recurrent neural networks [C]//Proc. Data Compression Conference (DCC). IEEE, 2019. DOI: 10.1109/dcc.2019.00087 |
| 16 | BELLARD F. Lossless data compression with neural networks [EB/OL]. (2019-05-04)[2024-11-20]. |
| 17 | LIU Q, XU Y L, LI Z. DecMac: a deep context model for high efficiency arithmetic coding [C]//Proc. International Conference on Artificial Intelligence in Information and Communication (ICAIIC). IEEE, 2019. DOI: 10.1109/icaiic.2019.8668843 |
| 18 | GOYAL M, TATWAWADI K, CHANDAK S, et al. DZip: improved general-purpose loss less compression based on novel neural network modeling [C]//Proc. Data Compression Conference (DCC). IEEE, 2021. DOI: 10.1109/dcc50243.2021.00023 |
| 19 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]//Proc. 31st International Conference on Neural Information Processing Systems. NIPS, 2017: 6000–6010 |
| 20 | HUANG C, XIE Y Q, JIANG Z Y, et al. Approximating human-like few-shot learning with GPT-based compression [EB/OL]. (2023-08-14)[2024-11-12]. |
| 21 | MITTU F, BU Y H, GUPTA A, et al. FineZip: pushing the limits of large language models for practical lossless text compression [EB/OL]. (2024-09-25)[2024-11-12]. |
| 22 | MAO Y, CUI Y F, KUO T W, et al. A fast transformer-based general-purpose lossless compressor [EB/OL]. (2022-03-30)[2024-11-12]. |
| 23 | NARASHIMAN S S, CHANDRACHOODAN N. AlphaZip: neural network-enhanced lossless text compression [EB/OL]. (2024-09-23)[2024-11-12]. |
| 24 | VALMEEKAM C S K, NARAYANAN K, KALATHIL D, et al. LLMZip: Lossless text compression using large language models [EB/OL]. (2023-06-06)[2024-11-12] |
| 25 | DELÉTANG G, RUOSS A, P-A DUQUENNE, et al. Language modeling is compression [EB/OL]. (2023-09-19)[2024-10-20]. |
| 26 | BOSE R C, RAY-CHAUDHURI D K. On a class of error correcting binary group codes [J]. Information and control, 1960, 3(1): 68–79. DOI: 10.1016/s0019-9958(60)90287-4 |
| 27 | GALLAGER R. Low-density parity-check codes [J]. IRE transactions on information theory, 1962, 8(1): 21–28. DOI: 10.1109/TIT.1962.1057683 |
| 28 | ARIKAN E. Channel polarization: a method for constructing capacity-achieving codes for symmetric binary-input memoryless channels [J]. IEEE transactions on information theory, 2009, 55(7): 3051–3073. DOI: 10.1109/TIT.2009.2021379 |
| 29 | NACHMANI E, BE'ERY Y, BURSHTEIN D. Learning to decode linear codes using deep learning [C]//Proc. 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton). IEEE, 2016: 341–346. DOI: 10.1109/ALLERTON.2016.7852251 |
| 30 | NACHMANI E, MARCIANO E, LUGOSCH L, et al. Deep learning methods for improved decoding of linear codes [J]. IEEE journal of selected topics in signal processing, 12(1): 119–131. DOI: 10.1109/jstsp.2017.2788405 |
| 31 | NACHMANI E, WOLF L. Hyper-graph-network decoders for block codes [C]//Proc. 33st International Conference on Neural Information Processing Systems. NIPS, 2019: 2329–2339 |
| 32 | CHOUKROUN Y, WOLF L. Error correction code transformer [C]//Proc. 36st International Conference on Neural Information Processing Systems. NIPS, 2022: 38695–38705 |
| 33 | HUANG J H, YUAN K, HUANG C, et al. D2 -JSCC: digital deep joint source-channel coding for semantic communications [EB/OL]. (2024-03-12)[2024-11-20]. |
| 34 | JIANG P W, WEN C K, YI X P, et al. Semantic communications using foundation models: design approaches and open issues [J]. IEEE wireless communications, 2024, 31(3): 76–84. DOI: 10.1109/MWC.002.2300460 |
| 35 | LIANG C S, DU H Y, SUN Y, et al. Generative AI-driven semantic communication networks: architecture, technologies and applications [J]. IEEE transaction on cognitive communications and networking, 2024, early access. DOI: 10.1109/TCCN.2024.3435524 |
| 36 | JIANG F B, PENG Y B, DONG L, et al. Large AI model-based semantic communications [J]. IEEE wireless communications, 31(3): 68–75. DOI: 10.1109/mwc.001.2300346 |
| 37 | GRASSUCCI E, BARBAROSSA S, COMMINIELLO D. Generative semantic communication: diffusion models beyond bit recovery [EB/OL]. (2023-06-07)[2024-11-12]. |
| 38 | CHANG M K, HSU C T, YANG G C. GenSC: generative semantic communication systems using BART-like model [J]. IEEE communications letters, 2024, 28(10): 2298–2302. DOI: 10.1109/LCOMM.2024.3450309 |
| 39 | GUO S S, WANG Y H, LI S J, et al. Semantic importance-aware communications using pre-trained language models [J]. IEEE communications letters, 2023, 27(9): 2328–2332. DOI: 10.1109/LCOMM.2023.3293805 |
| 40 | XIE H Q, QIN Z J, TAO X M, et al. Toward intelligent communications: large model empowered semantic communications [J]. IEEE communications magazine, 2025, 63(1): 69–75. DOI: 10.1109/MCOM.001.2300807 |
| 41 | QIAO L, MASHHADI M B, GAO Z, et al. Latency-aware generative semantic communications with pre-trained diffusion models [EB/OL]. (2024-03-05)[2024-11-12]. |
| 42 | JIANG F B, DONG L, PENG Y B, et al. Large AI model empowered multimodal semantic communications [J]. IEEE communications magazine, 2025, 63(1): 76–82. DOI: 10.1109/mcom.001.2300575 |
| 43 | YANG W T, XIONG Z H, MAO S W, et al. Rethinking generative semantic communication for multi-user systems with large language models [EB/OL]. (2024-08-16)[2024-11-12]. |
| 44 | SHANNON C E. A mathematical theory of communication [J]. Bell system technical journal, 1948, 27(3): 379–423. DOI: 10.1002/j.1538-7305.1948.tb01338.x |
| 45 | RISSANEN J J. Generalized kraft inequality and arithmetic coding [J]. IBM journal of research and development, 1976, 20(3): 198–203. DOI: 10.1147/rd.203.0198 |
| 46 | PASCO R. Source coding algorithms for fast data compression (Ph.D. Thesis abstr.) [J]. IEEE transactions on information theory, 1977, 23(4): 548. DOI: 10.1109/TIT.1977.1055739 |
| 47 | HOWARD P G, VITTER J S. Arithmetic coding for data compression [J]. Proceedings of the IEEE, 1994, 82(6): 857–865. DOI: 10.1109/5.286189 |
| 48 | BENNATAN A, CHOUKROUN Y, KISILEV P. Deep learning for decoding of linear codes: a syndrome-based approach [C]//Proc. IEEE International Symposium on Information Theory (ISIT). IEEE, 2018: 1595–1599. DOI: 10.1109/ISIT.2018.8437530 |
| 49 | KOEHN P. Europarl: a parallel corpus for statistical machine translation [C]//Proc. Machine Translation Summit. International Association for Machine Translation, 2005: 79–86 |
| 50 | RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2024-10-20]. |
| 51 | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]//Proc. 40th Annual Meeting on Association for Computational Linguistics. USAACL, 2001. DOI: 10.3115/1073083.1073135 |
| 52 | DEVLIN J, CHANG M-W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]//Proc. 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Association for Computational Linguistics, 2019: 4171–4186. DOI: 10.18653/v1/N19-1423 |
| 53 | CHOUKROUN Y, WOLF L. Denoising diffusion error correction codes [EB/OL]. (2022-09-16)[2024-11-12]. |
| 54 | HUANG Y Z, ZHANG J H, SHAN Z F, et al. Compression represents intelligence linearly [EB/OL]. (2024-04-15)[2024-11-12]. |
| 55 | PARK S J, KWAK H Y, KIM S H, et al. How to mask in error correction code transformer: systematic and double masking [EB/OL]. (2023-08-16)[2024-11-12]. |
| 56 | NGUYEN D T, KIM S. U-shaped error correction code transformers [J]. IEEE transactions on cognitive communications and networking, 2024: 1. DOI: 10.1109/tccn.2024.3482349 |
| 57 | HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [C]//Proc. 34th International Conference on Neural Information Processing Systems. NIPS, 2020: 6840–6851. DOI: 10.48550/arXiv.2006.11239 |
| 58 | CHOUKROUN Y, WOLF L. A foundation model for error correction codes [C]//12th International Conference on Learning Representations. ICLR, 2024. DOI: 10.48550/arXiv.2405.04050 |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

