ZTE Communications ›› 2025, Vol. 23 ›› Issue (3): 38-47.DOI: 10.12142/ZTECOM.202503005
• Special Topic • Previous Articles Next Articles
DU Linkang, SU Zhou( ), YU Xinyi
), YU Xinyi
Received:2025-06-20
Online:2025-09-11
Published:2025-09-11
Contact:
SU Zhou
About author:DU Linkang received his BE and PhD degrees from Zhejiang University, China in 2018 and 2023, respectively. He is currently an assistant professor at the School of Cyber Science and Engineering, Xi’an Jiaotong University, China. His research interests include privacy-preserving computing and trustworthy machine learning.Supported by:DU Linkang, SU Zhou, YU Xinyi. Dataset Copyright Auditing for Large Models: Fundamentals, Open Problems, and Future Directions[J]. ZTE Communications, 2025, 23(3): 38-47.
Add to citation manager EndNote|Ris|BibTeX
URL: https://zte.magtechjournal.com/EN/10.12142/ZTECOM.202503005
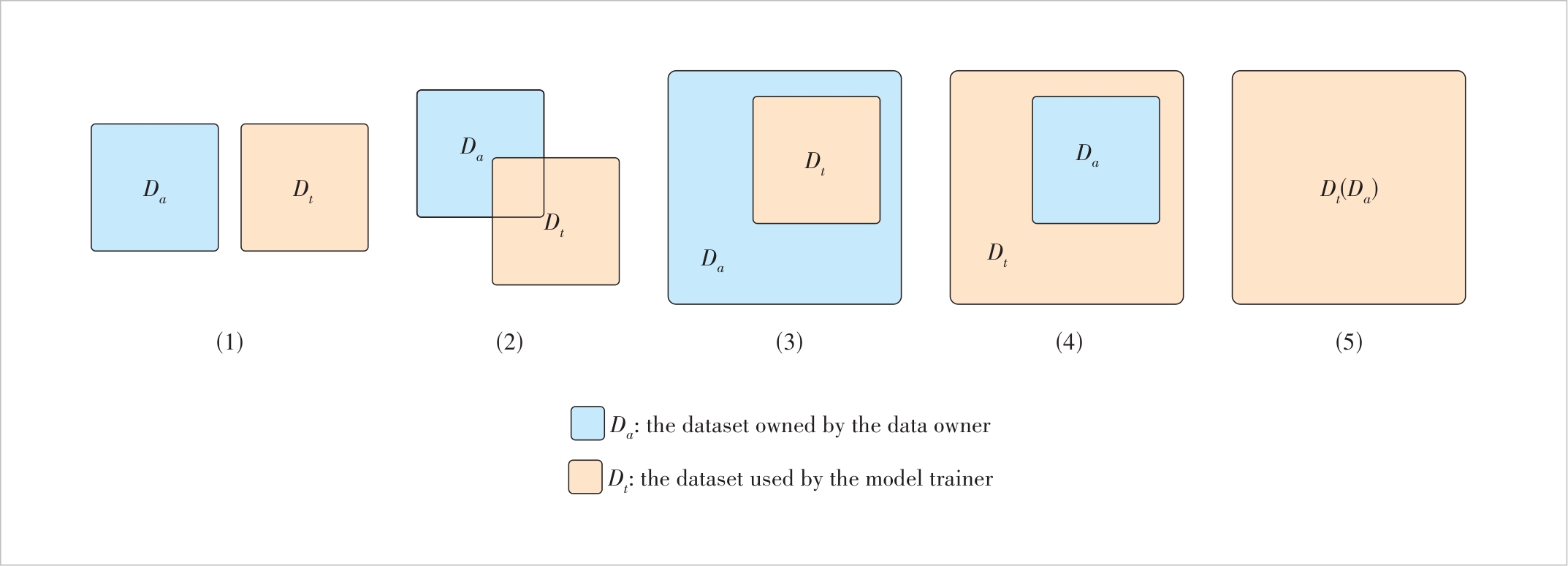
Figure 1 An illustration of data overlaps
| Reference | Domain | Type | Tech-nique | Stage of Use | Data Overlap | Model Access Level | Used Model | Used Dataset |
|---|---|---|---|---|---|---|---|---|
| CHEN et al.[ | Image | Intrusive | BA | Pre-training | Case 4 | Black-box | DeepID, VGG-Face | YouTube Aligned Face Dataset |
| HUANG et al.[ | FW | Pre-training | Case 2 | Black-box | SimCLR | CIFAR-10, CIFAR-100, and TinyImageNet | ||
| HUANG et al.[ | Pre-training | Case 4 | Black-box | ResNet-18, ResNet-34, WideResNet-28-2, VGG-16, ConvNetBN, and SimCLR | CIFAR-100 and TinyImageNet | |||
| HUANG et al.[ | Text | Intrusive | FW | Pre-training | Case 2 | Black-box | LLaMA 2 | SST2, AG’s news, and TweetEval (emoji) |
| SHI et al.[ | Non-intrusive | MI | Pre-training | Case 2 | Black-box | LLaMA (7 B, 13 B, 30 B, 65 B), GPT-NeoX-20B, OPT-66 B, Pythia-2.8 B, GPT-3 (text-davinci-003), and LLaMA2-7 B-WhoIsHarryPotter | WIKIMIA, Books3 (copyrighted books), RedPajama + downstream tasks (BoolQ, IMDB, TruthfulQA, CommonsenseQA), and Harry Potter series | |
| MAINI et al.[ | DI | Pre-training | Case 2 | Gray- box | Pythia (410 M, 1.4 B, 6.9 B, and 12 B) | PILE (20 subsets including Wiki, Arxiv, OpenWebText, etc.) | ||
| MA et al.[ | Fine-tuning | Case 4 | Black-box | CodeGen, GPT-Neo, CodeGPT, InCoder, PolyCoder, and CodeT5 | APPS, PY150, MBPP, and MBXP (multi-language versions) | |||
| WANG et al.[ | Text- image | Intrusive | BA | Fine-tuning | Case 4, Case 5 | Black-box | Stable Diffusion v2.1 | WikiArt and COCO |
| REN et al.[ | Fine-tuning | Case 3, Case 5 | Black-box | Stable Diffusion v1.4 and Stable Diffusion v2 | CC-20k, Sketchyscene, and Cartoon-BLIP-Caption | |||
| LI et al.[ | Fine-tuning | Case 4 | Black-box | Stable Diffusion v1.5, Stable Diffusion v2.1, and Kandinsky 2.2 | CelebA-HQ, ArtBench, Landscape, MS-COCO, and Pokémon BLIP captions dataset | |||
| HUANG et al.[ | FW | Pre-training | Case 2 | Black-box | CLIP | Flickr30k | ||
CUI et al.[ | Fine-tuning | Case 3, Case 5 | Black-box | Stable Diffusion | WikiArt, Pokémon BLIP captions dataset, and CelebA | |||
| HUANG et al.[ | Pre-training | Case 4 | Black-box | CLIP | Flickr30k | |||
| DU et al.[ | Non-intrusive | DI | Fine-tuning | Case 1, Case 2, Case 5 | Black-box | Diffusion v2.1, Stable Diffusion XL, and Kandinsky | WikiArt and Artist-30 |
Table 1 A summary of existing solutions for dataset copyright auditing in the context of large models, with papers organized by audit domain and type
| Reference | Domain | Type | Tech-nique | Stage of Use | Data Overlap | Model Access Level | Used Model | Used Dataset |
|---|---|---|---|---|---|---|---|---|
| CHEN et al.[ | Image | Intrusive | BA | Pre-training | Case 4 | Black-box | DeepID, VGG-Face | YouTube Aligned Face Dataset |
| HUANG et al.[ | FW | Pre-training | Case 2 | Black-box | SimCLR | CIFAR-10, CIFAR-100, and TinyImageNet | ||
| HUANG et al.[ | Pre-training | Case 4 | Black-box | ResNet-18, ResNet-34, WideResNet-28-2, VGG-16, ConvNetBN, and SimCLR | CIFAR-100 and TinyImageNet | |||
| HUANG et al.[ | Text | Intrusive | FW | Pre-training | Case 2 | Black-box | LLaMA 2 | SST2, AG’s news, and TweetEval (emoji) |
| SHI et al.[ | Non-intrusive | MI | Pre-training | Case 2 | Black-box | LLaMA (7 B, 13 B, 30 B, 65 B), GPT-NeoX-20B, OPT-66 B, Pythia-2.8 B, GPT-3 (text-davinci-003), and LLaMA2-7 B-WhoIsHarryPotter | WIKIMIA, Books3 (copyrighted books), RedPajama + downstream tasks (BoolQ, IMDB, TruthfulQA, CommonsenseQA), and Harry Potter series | |
| MAINI et al.[ | DI | Pre-training | Case 2 | Gray- box | Pythia (410 M, 1.4 B, 6.9 B, and 12 B) | PILE (20 subsets including Wiki, Arxiv, OpenWebText, etc.) | ||
| MA et al.[ | Fine-tuning | Case 4 | Black-box | CodeGen, GPT-Neo, CodeGPT, InCoder, PolyCoder, and CodeT5 | APPS, PY150, MBPP, and MBXP (multi-language versions) | |||
| WANG et al.[ | Text- image | Intrusive | BA | Fine-tuning | Case 4, Case 5 | Black-box | Stable Diffusion v2.1 | WikiArt and COCO |
| REN et al.[ | Fine-tuning | Case 3, Case 5 | Black-box | Stable Diffusion v1.4 and Stable Diffusion v2 | CC-20k, Sketchyscene, and Cartoon-BLIP-Caption | |||
| LI et al.[ | Fine-tuning | Case 4 | Black-box | Stable Diffusion v1.5, Stable Diffusion v2.1, and Kandinsky 2.2 | CelebA-HQ, ArtBench, Landscape, MS-COCO, and Pokémon BLIP captions dataset | |||
| HUANG et al.[ | FW | Pre-training | Case 2 | Black-box | CLIP | Flickr30k | ||
CUI et al.[ | Fine-tuning | Case 3, Case 5 | Black-box | Stable Diffusion | WikiArt, Pokémon BLIP captions dataset, and CelebA | |||
| HUANG et al.[ | Pre-training | Case 4 | Black-box | CLIP | Flickr30k | |||
| DU et al.[ | Non-intrusive | DI | Fine-tuning | Case 1, Case 2, Case 5 | Black-box | Diffusion v2.1, Stable Diffusion XL, and Kandinsky | WikiArt and Artist-30 |
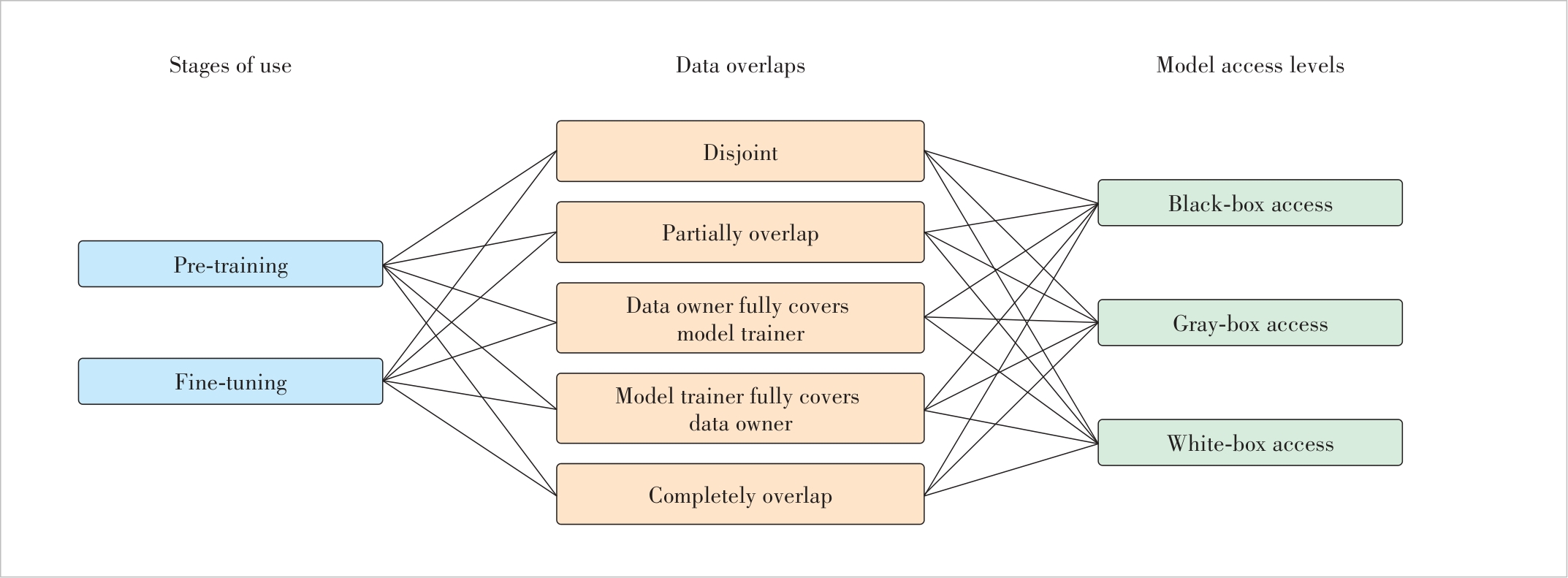
Figure 2 Combinations of auditing settings
| Reference | Domain | Model | Dataset | Type | TPR@FPR=0.05 |
|---|---|---|---|---|---|
| CHEN et al.[ | Image | ResNet18 | CIFAR-10 | Intrusive | 0.155 6 |
| HUANG et al.[ | 0.587 7 | ||||
| SHI et al.[ | Text | LLaMA-7B | Wiki | Non-intrusive | 0.147 9 |
| MAINI et al.[ | 0.068 1 | ||||
| WANG et al.[ | Text-image | Stable Diffusion v2.1 | Pokémon BLIP captions dataset | Intrusive | 0.220 0 |
| REN et al.[ | 0.550 0 | ||||
| LI et al.[ | 0.686 7 | ||||
| CUI et al.[ | 0.626 7 | ||||
| DU et al.[ | Text-image | Stable Diffusion v2.1 | Pokémon BLIP captions dataset | Non-intrusive | 0.833 0 |
Table 2 Performance evaluation of methods, where the injection rate for intrusive methods is fixed at 2%
| Reference | Domain | Model | Dataset | Type | TPR@FPR=0.05 |
|---|---|---|---|---|---|
| CHEN et al.[ | Image | ResNet18 | CIFAR-10 | Intrusive | 0.155 6 |
| HUANG et al.[ | 0.587 7 | ||||
| SHI et al.[ | Text | LLaMA-7B | Wiki | Non-intrusive | 0.147 9 |
| MAINI et al.[ | 0.068 1 | ||||
| WANG et al.[ | Text-image | Stable Diffusion v2.1 | Pokémon BLIP captions dataset | Intrusive | 0.220 0 |
| REN et al.[ | 0.550 0 | ||||
| LI et al.[ | 0.686 7 | ||||
| CUI et al.[ | 0.626 7 | ||||
| DU et al.[ | Text-image | Stable Diffusion v2.1 | Pokémon BLIP captions dataset | Non-intrusive | 0.833 0 |
| Reference | |||||||
|---|---|---|---|---|---|---|---|
| WANG et al.[ | 0.2 | 0.220 0 | 0.353 3 | 0.650 9 | 0.777 8 | 0.866 7 | 0.936 9 |
| REN et al.[ | 0.086 7 | 0.120 0 | 0.940 0 | 0.993 3 | 1.000 0 | 1.000 0 | 1.000 0 |
| LI et al.[ | 0.233 3 | 0.686 7 | 0.726 7 | 0.980 0 | 0.993 3 | 1.000 0 | 1.000 0 |
| CUI et al.[ | 0.006 7 | 0.626 7 | 0.640 0 | 0.653 3 | 0.746 7 | 0.913 3 | 1.000 0 |
Table 3 Performance evaluation of intrusive methods under different injection rates, whereα denotes the injection rate
| Reference | |||||||
|---|---|---|---|---|---|---|---|
| WANG et al.[ | 0.2 | 0.220 0 | 0.353 3 | 0.650 9 | 0.777 8 | 0.866 7 | 0.936 9 |
| REN et al.[ | 0.086 7 | 0.120 0 | 0.940 0 | 0.993 3 | 1.000 0 | 1.000 0 | 1.000 0 |
| LI et al.[ | 0.233 3 | 0.686 7 | 0.726 7 | 0.980 0 | 0.993 3 | 1.000 0 | 1.000 0 |
| CUI et al.[ | 0.006 7 | 0.626 7 | 0.640 0 | 0.653 3 | 0.746 7 | 0.913 3 | 1.000 0 |
| [1] | LIANG Z, XU Y, HONG Y, et al. A survey of multimodel large language models [C]//Proceedings of the 3rd International Conference on Computer, Artificial Intelligence and Control Engineering. ACM, 2024: 405–409. DOI: 10.1145/3672758.3672824 |
| [2] | TRUMMER I. Large language models: principles and practice [C]//Proceedings of IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 2024: 5354–5357. DOI: 10.1109/ICDE60146.2024.00404 |
| [3] | ZHU X P, YAO H D, LIU J, et al. Review of evolution of large language model algorithms [J]. ZTE technology journal, 2024, 30(2): 9–20. DOI: 10.12142/ZTETJ.202402003 |
| [4] | TIAN H D, ZHANG M Z, CHANG R, et al. A survey on large model training technologies [J]. ZTE technology journal, 2024, 30(2): 21–28. DOI: 10.12142/ZTETJ.202402004 |
| [5] | WANG Y T, PAN Y H, SU Z, et al. Large model based agents: state-of-the-art, cooperation paradigms, security and privacy, and future trends [EB/OL]. (2024‑09‑22) [2025‑06‑14]. |
| [6] | SAMEK W, MONTAVON G, LAPUSCHKIN S, et al. Explaining deep neural networks and beyond: a review of methods and applications [J]. Proceedings of the IEEE, 2021, 109(3): 247–278 |
| [7] | CHANG Y P, WANG X, WANG J D, et al. A survey on evaluation of large language models [J]. ACM transactions on intelligent systems and technology, 2024, 15(3): 1–45. DOI: 10.1145/3641289 |
| [8] | WIGGERS K. OpenAI claims to have hit $10 B in annual revenue [EB/OL]. (2025‑06‑09) [2025‑06‑14]. |
| [9] | SCHREINERM. GPT‑4 architecture, datasets, costs and more leaked [EB/OL]. (2023‑06‑28) [2025‑06‑14]. |
| [10] | COULTER M. Getty images sues stability AI in UK copyright test case [EB/OL]. (2025-06-09) [2025-06-14]. |
| [11] | ENGLUND S, MARINO Z. Client alert: court decides that use of copyrighted works in AI training is not fair use: Thomson Reuters Enterprise Centre GmbH v.s. Ross Intelligence Inc. [EB/OL]. (2025‑02‑12) [2025‑06‑14]. |
| [12] | GOODMAN D. Thomson Reuters wins AI copyright ‘fair use’ ruling against one‑time competitor [EB/OL]. (2025‑02‑11) [2025‑06‑14]. |
| [13] | MORALES J. Meta staff torrented nearly 82 TB of pirated books for AI training [EB/OL]. (2025‑02‑09) [2025‑06‑14]. |
| [14] | WEIR K. This is how Meta AI staffers deemed more than 7 million books to have no “economic value” [EB/OL]. (2025‑04‑15) [2025‑06‑14]. |
| [15] | GUO J F, LI Y M, CHEN R B, et al. Zeromark: towards dataset ownership verification without disclosing watermark [C]//International Conference on Neural Information Processing Systems. ACM, 2024: 120468–120500 |
| [16] | LI Y M, BAI Y, JIANG Y, et al. Untargeted backdoor watermark: towards harmless and stealthy dataset copyright protection [C]//International Conference on Neural Information Processing Systems. ACM, 2022: 13238–13250 |
| [17] | LI Y Z, LI Y M, WU B Y, et al. Invisible backdoor attack with sample-specific triggers [C]//International Conference on Computer Vision (ICCV). IEEE, 2021: 16443–16452. DOI: 10.1109/ICCV48922.2021.01615 |
| [18] | SZYLLER S, ZHANG R, LIU J, et al. On the robustness of dataset inference [EB/OL]. (2023‑06‑15) [2025‑06‑14]. |
| [19] | MAINI P, YAGHINI M, PAPERNOT N. Dataset inference: ownership resolution in machine learning [EB/OL]. [2025‑06‑14]. |
| [20] | LIU G Y, XU T L, MA X Q, et al. Your model trains on my data protecting intellectual property of training data via membership fingerprint authentication [J]. IEEE transactions on information forensics and security, 2022, 17: 1024–1037. DOI: 10.1109/TIFS.2022.3155921 |
| [21] | REN K, YANG Z Q, LU L, et al. SoK: on the role and future of AIGC watermarking in the era of Gen-AI [EB/OL]. [2025‑06‑14]. |
| [22] | HARTMANN V, SURI A, BINDSCHAEDLER V, et al. Sok: memorization in general-purpose large language models [EB/OL]. (2023‑10‑24) [2025‑06‑14]. DOI: 10.48550/arXiv.2310.18362 |
| [23] | DU L K, ZHOU X R, CHEN M, et al. SoK: dataset copyright auditing in machine learning systems [EB/OL]. (2024‑10‑22) [2025‑06‑14]. DOI: 10.48550/arXiv.2410.16618 |
| [24] | DONG T, LI S F, CHEN G X, et al. RAI2: responsible identity audit governing the artificial intelligence [EB/OL]. [2025‑06‑14]. . DOI: 10.14722/ndss.2023.241012 |
| [25] | CHEN X Y, LIU C, LI B, et al. Targeted backdoor attacks on deep learning systems using data poisoning [EB/OL]. [2025‑06‑14]. |
| [26] | WANG S R, ZHU Y B, TONG W, et al. Detecting dataset abuse in fine-tuning stable diffusion models for text-to-image synthesis [EB/OL]. (2024‑09‑27) [2025‑06‑14]. |
| [27] | REN J, CUI Y Q, CHEN C, et al. EnTruth: enhancing the traceability of unauthorized dataset usage in text-to-image diffusion models with minimal and robust alterations [EB/OL]. (2024-06-20) [2025‑06‑14]. |
| [28] | LI B H, WEI Y H, FU Y K, et al. Towards reliable verification of unauthorized data usage in personalized text-to-image diffusion models [EB/OL]. (2024‑10‑14) [2025‑06‑14]. |
| [29] | HUANG Z H, GONG N Z, REITER M K. A general framework for data-use auditing of ML models [C]//ACM SIGSAC Conference on Computer and Communications Security. ACM, 2024: 1300–1314. DOI: 10.1145/3658644.3690226 |
| [30] | CUI Y Q, REN J, LIN Y P, et al. FT-shield: a watermark against unauthorized fine-tuning in text-to-image diffusion models [J]. ACM SIGKDD explorations newsletter, 2025, 26(2): 76–88. DOI: 10.1145/3715073.3715080 |
| [31] | HUANG Z H, GONG N Z, REITER M K. Instance-level data-use auditing of visual ML models [EB/OL]. (2025‑03‑28) [2025‑06‑14]. |
| [32] | SHI W J, AJITH A, XIA M Z, et al. Detecting pretraining data from large language models [EB/OL]. [2025‑06‑14]. |
| [33] | MAINI P, JIA H R, PAPERNOT N, et al. LLM dataset inference: did you train on my dataset [C]//International Conference on Neural Information Processing Systems. ACM, 2024: 124069–124092. DOI: 10.48550/arXiv.2406.06443 |
| [34] | MA W L, SONG Y L, XUE M H, et al. The “code” of ethics: a holistic audit of AI code generators [J]. IEEE transactions on dependable and secure computing, 2024, 21(5): 4997–5013. DOI: 10.1109/TDSC.2024.3367737 |
| [35] | DU L K, ZHU Z, CHEN M, et al. ArtistAuditor: auditing artist style pirate in text-to-image generation models [C]//Proceedings of the ACM on Web Conference 2025. ACM, 2025: 2500–2513. DOI: 10.1145/3696410.3714602 |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

