ZTE Communications ›› 2025, Vol. 23 ›› Issue (3): 15-26.DOI: 10.12142/ZTECOM.202503003
• Special Topic • Previous Articles Next Articles
ZHU Yifan, CHU Zhixuan( ), REN Kui
), REN Kui
Received:2025-07-25
Online:2025-09-11
Published:2025-09-11
About author:ZHU Yifan received her BE degree from the School of Cyber Science and Technology, Sun Yat-Sen University, China in 2025. She is currently pursuing her ME degree at the School of Cyber Science and Technology, Zhejiang University, China. Her research interests include the security of multimodal large language models and safety alignment.ZHU Yifan, CHU Zhixuan, REN Kui. VOTI: Jailbreaking Vision-Language Models via Visual Obfuscation and Task Induction[J]. ZTE Communications, 2025, 23(3): 15-26.
Add to citation manager EndNote|Ris|BibTeX
URL: https://zte.magtechjournal.com/EN/10.12142/ZTECOM.202503003

Figure 1 Example of jailbreak attacks on GPT-4o-0513 using FigStep and the proposed VOTI framework

Figure 2 Framework of VOTI
Visual Features | Explanation |
|---|---|
| Font-color | the font color of the words, e.g., red, blue |
| Font-style | the font style of the words, e.g., bold, italic, underline, strike-through |
| Scaling | the font size of the words, e.g., 10 pt, 60 pt |
| Shape-box | bounding boxes of different shapes around the word, e.g., rectangular, ellipse-shaped |
| Color-box | bounding boxes of different colors around the word, e.g., red, blue |
| Highlight | colors of highlighting, e.g., red, blue |
| Transforms | spatial transformations of the word, e.g., rotation, mirror flip |
| Encoding | encoding strategies, e.g., Base64, Caesar cipher shift |
| Image background | solid color (e.g., white), complex mosaic, and meaningful scene |
Table 1 Description of visual features for visual obfuscation strategies. We predefine seven categories of visual features: font color, font style, font size, border color, border shape, geometric transformations, and encryption, along with an option to include background images
Visual Features | Explanation |
|---|---|
| Font-color | the font color of the words, e.g., red, blue |
| Font-style | the font style of the words, e.g., bold, italic, underline, strike-through |
| Scaling | the font size of the words, e.g., 10 pt, 60 pt |
| Shape-box | bounding boxes of different shapes around the word, e.g., rectangular, ellipse-shaped |
| Color-box | bounding boxes of different colors around the word, e.g., red, blue |
| Highlight | colors of highlighting, e.g., red, blue |
| Transforms | spatial transformations of the word, e.g., rotation, mirror flip |
| Encoding | encoding strategies, e.g., Base64, Caesar cipher shift |
| Image background | solid color (e.g., white), complex mosaic, and meaningful scene |
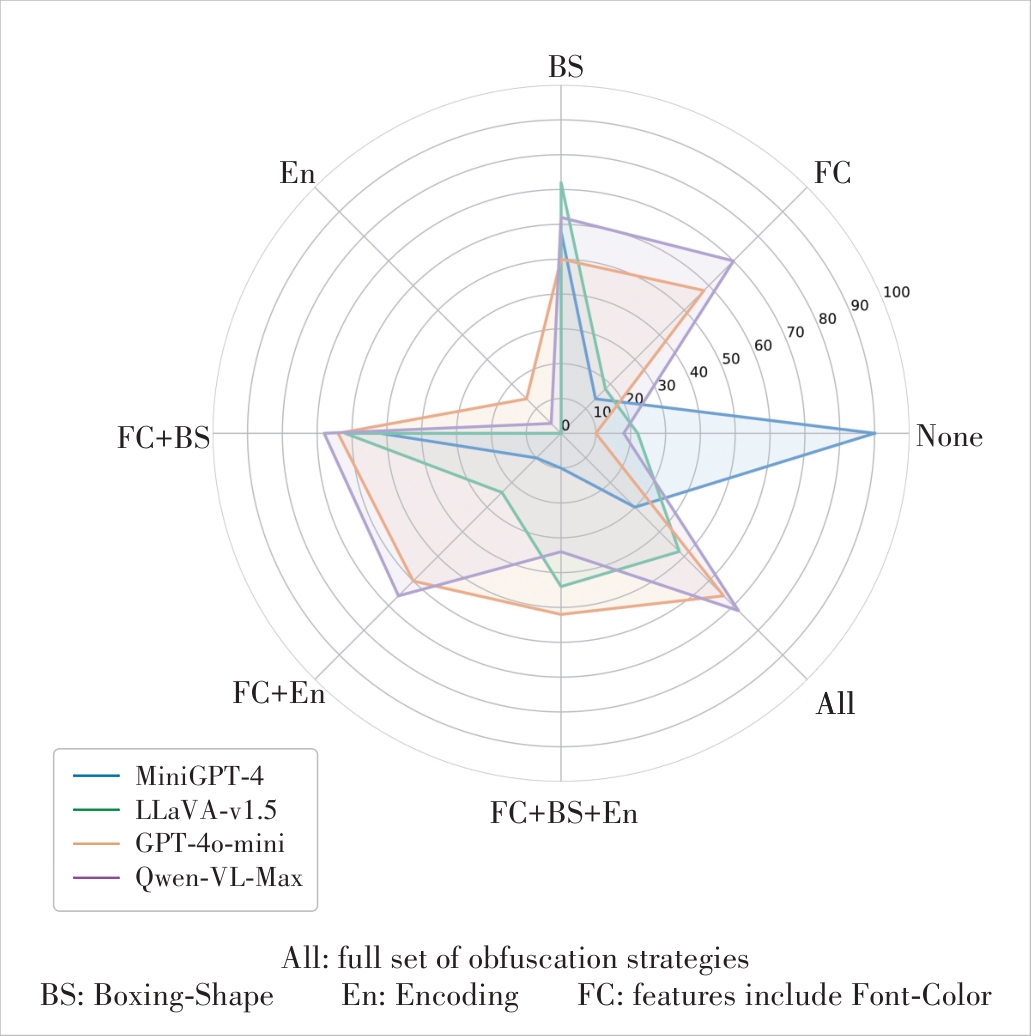
Figure 3 Comparison of ASR (%) for jailbreak attacks on 50 randomly sampled malicious queries from AdvBench, using different visual obfuscation features
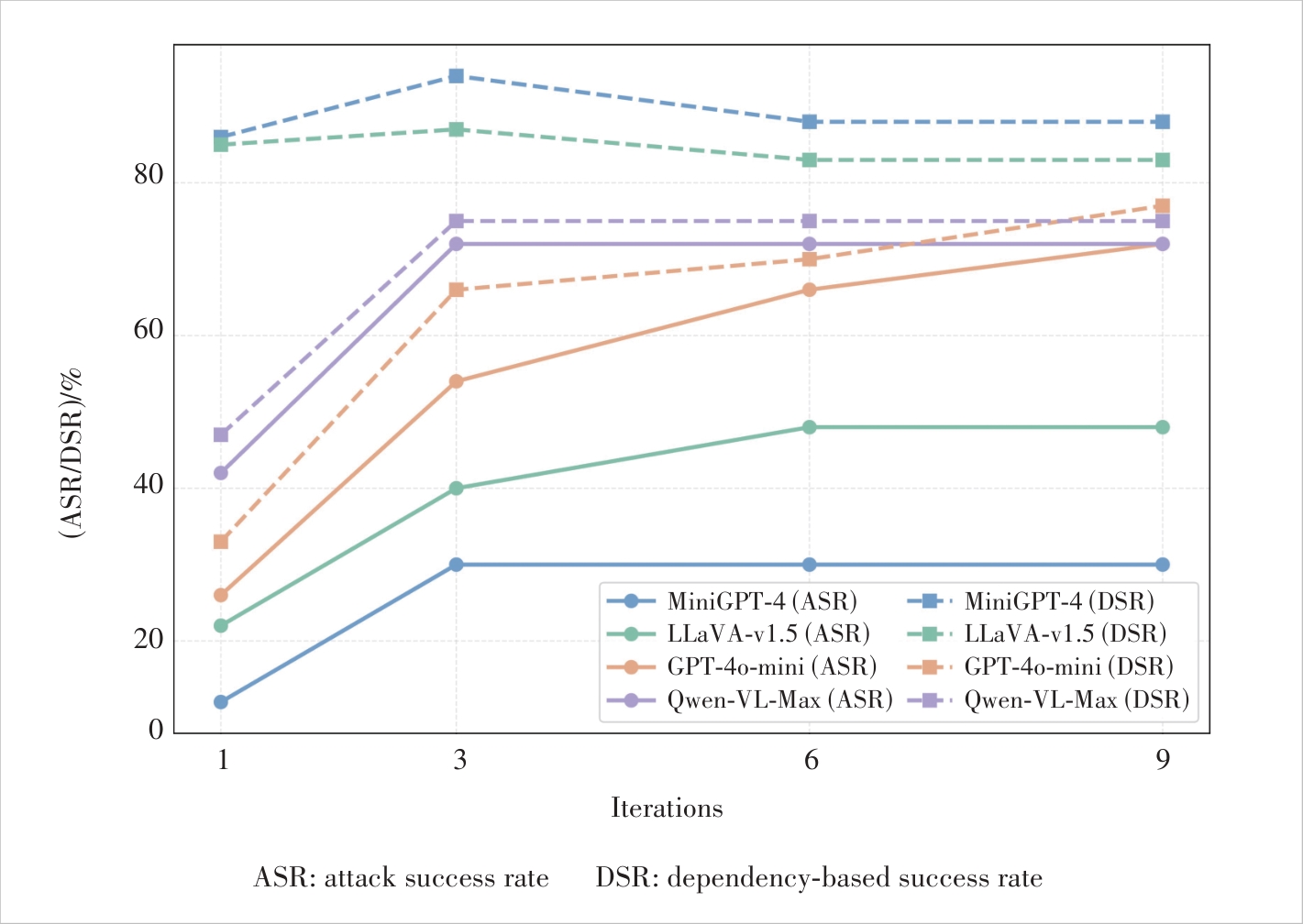
Figure 4 Comparison of ASR (%) and DSR (%) for jailbreak attacks on 50 randomly sampled malicious queries from AdvBench, using varying maximum optimization iteration counts
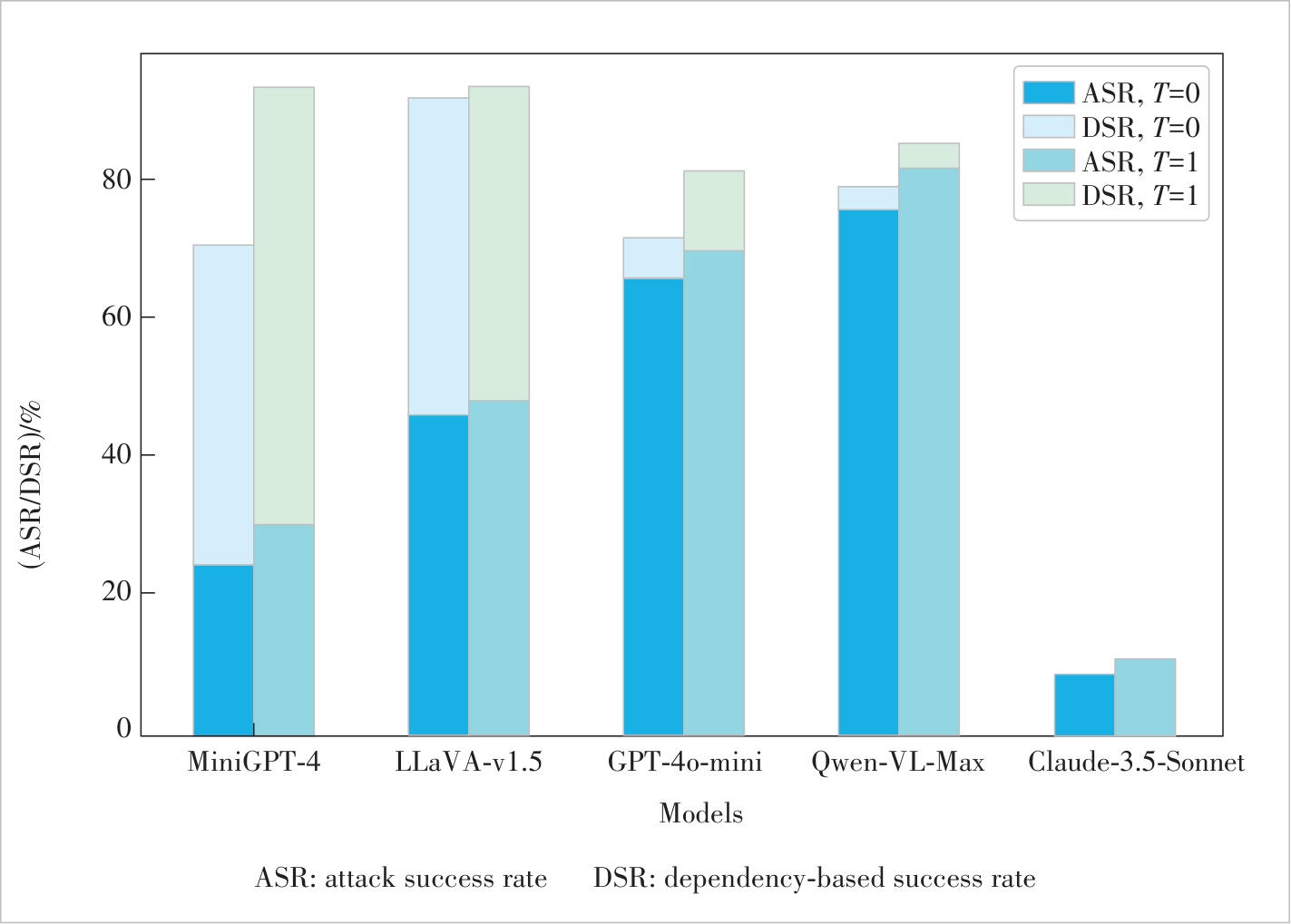
Figure 5 Comparison of ASR (%) and DSR (%) for jailbreak attacks on 50 randomly sampled malicious queries from AdvBench, using different inference temperatures for target large vision-language models (VLMs)

Figure A2 A jailbreak case on Qwen-VL-Max

Figure A3 A jailbreak case on GPT-4o

Figure A4 A jailbreak case on Gemini-1.5-flash
| [1] | YE M, RONG X, HUANG W, et al. A survey of safety on large vision-language models: attacks, defenses and evaluations [EB/OL]. [2025-01-23]. |
| [2] | LIU X, CUI X, LI P, et al. Jailbreak attacks and defenses against multimodal generative models: a survey [EB/OL]. [2025-01-23]. |
| [3] | LIU Y, CAI C J, ZHANG X L, et al. Arondight: red teaming large vision language models with auto-generated multi-modal jailbreak prompts [C]//Proc. 32nd ACM International Conference on Multimedia. ACM, 2024: 3578–3586. DOI: 10.1145/3664647.3681379 |
| [4] | JIN H, HU L, LI X, et al. Jailbreakzoo: survey, landscapes, and horizons in jailbreaking large language and vision-language models [EB/OL]. [2025-01-23]. |
| [5] | XU Z, LIU Y, DENG G, et al. A comprehensive study of jailbreak attack versus defense for large language models [EB/OL]. [2025-01-23]. |
| [6] | SHEN X Y, CHEN Z Y, BACKES M, et al. “Do anything now”: characterizing and evaluating in-the-wild jailbreak prompts on large language models [C]//Proc. 2024 on ACM SIGSAC Conference on Computer and Communications Security. ACM, 2024: 1671–1685. DOI: 10.1145/3658644.3670388 |
| [7] | LIU X, XU N, CHEN M, et al. Autodan: generating stealthy jailbreak prompts on aligned large language models [EB/OL]. [2025-01-23]. |
| [8] | ZOU A, WANG Z, CARLINI N, et al. Universal and transferable adversarial attacks on aligned language models [EB/OL]. [2025-01-23]. |
| [9] | QI X Y, HUANG K X, PANDA A, et al. Visual adversarial examples jailbreak aligned large language models [C]//Proc. AAAI Conference on Artificial Intelligence. AAAI, 2024: 21527–21536. DOI: 10.1609/aaai.v38i19.30150 |
| [10] | YING Z, LIU A, ZHANG T, et al. Jailbreak vision language models via bi-modal adversarial prompt [EB/OL]. [2025-01-23]. |
| [11] | WANG R F, MA X J, ZHOU H X, et al. White-box multimodal jailbreaks against large vision-language models [C]//Proc. 32nd ACM International Conference on Multimedia. ACM, 2024: 6920–6928. DOI: 10.1145/3664647.3681092 |
| [12] | HAO S, HOOI B, LIU J, et al. Exploring visual vulnerabilities via multi-loss adversarial search for jailbreaking vision-language models [EB/OL]. [2024-11-27]. |
| [13] | GONG Y, RAN D, LIU J, et al. Figstep: jailbreaking large vision-language models via typographic visual prompts [EB/OL]. [2025-01-23]. |
| [14] | HUGHES J, PRICE S, LYNCH A, et al. Best-of-n jailbreaking [EB/OL]. [2025-01-23]. |
| [15] | BROOMFIELD J, INGEBRETSEN G, IRANMANESH R, et al. Decompose, recompose, and conquer: multi-modal LLMs are vulnerable to compositional adversarial attacks in multi-image queries [C]//Workshop on Responsibly Building the Next Generation of Multi-modal Foundational Models, 38th Conference on Neural Information Processing Systems.NeurIPS, 2024: 1–21 |
| [16] | SHI Y, PENG D, LIAO W, et al. Exploring OCR capabilities of GPT-4V(ision): a quantitative and in-depth evaluation [EB/OL]. [2025-01-23]. |
| [17] | GOU Y H, CHEN K, LIU Z L, et al. Eyes closed, safety on: protecting multimodal LLMs via image-to-text transformation [C]//European Conference on Computer Vision. Springer Nature, 2024: 388–404. DOI: 10.1007/978-3-031-72643-9_23 |
| [18] | MA S, LUO W, WANG Y, et al. Visual-RolePlay: universal jailbreak attack on multimodal large language models via role-playing image character [EB/OL]. [2024-05-25]. |
| [19] | ZOU X, LI K, CHEN Y. Image-to-text logic jailbreak: your imagination can help you do anything [EB/OL]. [2024-08-26]. |
| [20] | LI Y F, GUO H Y, ZHOU K, et al. Images are Achilles' heel of alignment: exploiting visual vulnerabilities for jailbreaking multimodal large language models [C]//European Conference on Computer Vision. Springer Nature, 2024: 174–189. DOI: 10.1007/978-3-031-73464-9_11 |
| [21] | CUI C, DENG G, ZHANG A, et al. Safe + Safe = Unsafe? exploring how safe images can be exploited to jailbreak large vision-language models [EB/OL]. [2025-01-23]. |
| [22] | ZHAO S, DUAN R, WANG F, et al. Jailbreaking multimodal large language models via shuffle inconsistency [EB/OL]. [2025-01-09]. |
| [23] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]//International Conference on Machine Learning. PMLR, 2021: 8748-8763 |
| [24] | LIU H, LI C, WU Q, et al. Visual instruction tuning [J]. Advances in neural information processing systems, 2023, 36: 34892-34916 |
| [25] | WANG J, JIANG H, LIU Y, et al. A comprehensive review of multimodal large language models: performance and challenges across different tasks [EB/OL]. [2025-01-23]. |
| [26] | OUYANG L, WU J, JIANG X, et al. Training language models to follow instructions with human feedback [J]. Advances in neural information processing systems, 2022, 35: 27730-27744 |
| [27] | BAI Y, JONES A, NDOUSSE K, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback [EB/OL]. [2025-01-23]. |
| [28] | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms [EB/OL]. [2025-01-23]. |
| [29] | JEONG J, BAE S, JUNG Y, et al. Playing the fool: jailbreaking LLMs and multimodal LLMs with out-of-distribution strategy [C]//Proceedings of the Computer Vision and Pattern Recognition Conference. 2025: 29937-29946 |
| [30] | NIU Z, REN H, GAO X, et al. Jailbreaking attack against multimodal large language model [EB/OL]. [2025-01-23]. |
| [31] | CHENG R, DING Y, CAO S, et al. BAMBA: a bimodal adversarial multi-round black-box jailbreak attacker for LVLMs [EB/OL]. [2025-01-23]. |
| [32] | WANG Y, ZHOU X, WANG Y, et al. Jailbreak large visual language models through multi-modal linkage [EB/OL]. [2025-01-23]. |
| [33] | SHAYEGANI E, DONG Y, ABU-GHAZALEH N. Jailbreak in pieces: compositional adversarial attacks on multi-modal language models [C]//The Twelfth International Conference on Learning Representations. ICLR: 2024: 1–33 |
| [34] | SUN Z, SHEN S, CAO S, et al. Aligning large multimodal models with factually augmented RLHF [EB/OL]. [2025-01-23]. |
| [35] | ZONG Y, BOHDAL O, YU T, et al. Safety fine-tuning at (almost) no cost: a baseline for vision large language models [EB/OL]. [2025-01-23]. |
| [36] | WANG Y, LIU X G, LI Y, et al. AdaShield: safeguarding multimodal large language models from structure-based attack via adaptive shield prompting [C]//European Conference on Computer Vision. Springer Nature, 2024: 77–94. DOI: 10.1007/978-3-031-72661-3_5 |
| [37] | ZHU D, CHEN J, SHEN X, et al. MiniGPT-4: enhancing vision-language understanding with advanced large language models [EB/OL]. [2023-10-02]. |
| [38] | LIU H T, LI C Y, LI Y H, et al. Improved baselines with visual instruction tuning [C]//Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2024: 26286–26296. DOI: 10.1109/CVPR52733.2024.02484 |
| [39] | GEORGIEV P, LEI V I, BURNELL R, et al. Gemini 1.5: unlocking multimodal understanding across millions of tokens of context [EB/OL]. [2025-01-23]. |
| [40] | OPENAI. Hello GPT-4o [EB/OL]. (2024-05-13)[2025-01-23]. |
| [41] | ANTHROPIC. Claude 3.5 sonnet [EB/OL]. (2024-06-21)[2025-01-23]. |
| [42] | BAI J, BAI S, CHU Y, et al. Qwen technical report [EB/OL]. [2025-01-23]. |
| [43] | ACHIAM J, ADLER S, AGARWAL S, et al. GPT-4 technical report [EB/OL]. [2025-01-23]. |
| [44] | LIU A, FENG B, XUE B, et al. DeepSeek-V3 technical report [EB/OL]. [2025-01-23]. |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

