ZTE Communications ›› 2019, Vol. 17 ›› Issue (2): 59-66.DOI: 10.12142/ZTECOM.201902009
• Research Paper • Previous Articles
ZUO Chunxue1, WANG Fang1, TANG Xiaolan2, ZHANG Yucheng1, FENG Dan1
Received:2018-06-09
Online:2019-06-11
Published:2019-11-14
About author:ZUO Chunxue (Supported by:ZUO Chunxue, WANG Fang, TANG Xiaolan, ZHANG Yucheng, FENG Dan. SRSC: Improving Restore Performance for Deduplication-Based Storage Systems[J]. ZTE Communications, 2019, 17(2): 59-66.
Add to citation manager EndNote|Ris|BibTeX
URL: https://zte.magtechjournal.com/EN/10.12142/ZTECOM.201902009

Figure 1. Fragmentation appears between two backup streams. The shaded chunks represent the chunks referenced by the second backup in each container. The blank areas offer extra space of the half-full containers when a backup completes.
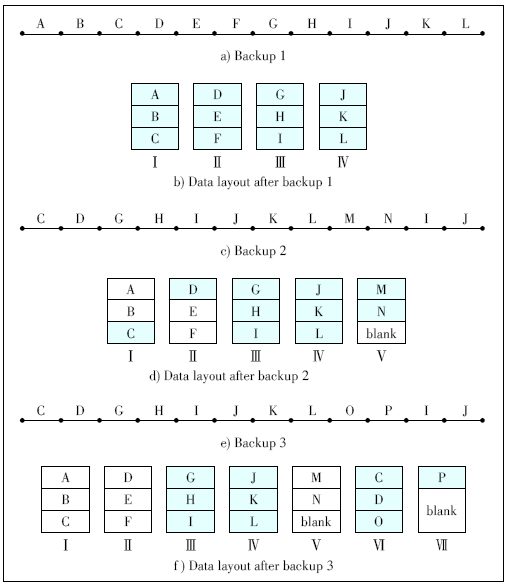
Figure 2. An example of three consecutive backups with the HAR rewriting scheme. The shaded chunks represent the chunks referenced by the current backup in each container.
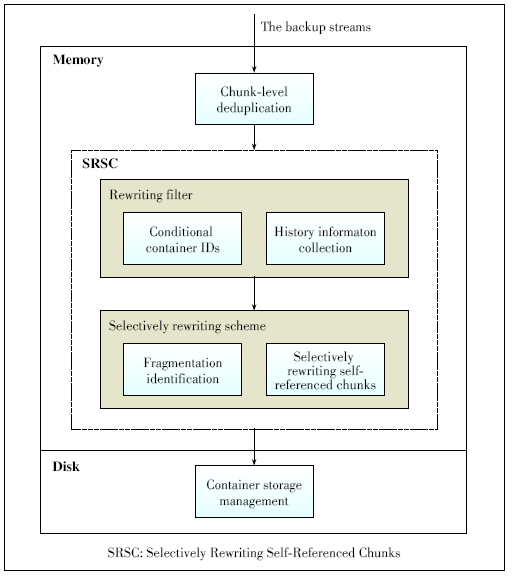
Figure 3. Modules and main data structure of SRSC.
| Dataset name | Total size (GB) | Version number | Deduplication ratio |
|---|---|---|---|
| WEBS | 105 | 35 | 73% |
| VMDK | 550 | 30 | 92% |
| FSLHomes | 860 | 20 | 91% |
Table 1 Characteristics of three datasets.
| Dataset name | Total size (GB) | Version number | Deduplication ratio |
|---|---|---|---|
| WEBS | 105 | 35 | 73% |
| VMDK | 550 | 30 | 92% |
| FSLHomes | 860 | 20 | 91% |

Figure 4. The comparisons between SRSC and HAR in terms of deduplication ratio based on the three datasets.

Figure 5. The comparisons between SRSC and HAR in terms of restore performance. The cache is 256-, 128-, and 256-container-sized in WEBS, VMDK and FSLHomes respectively.

Figure. 6 The comparisons between SRSC and HAR in terms of restore performance under different cache sizes.
| [1] | ZHU B, LI K, PATTERSON H. Avoiding the Disk Bottleneck in the Data Domain Deduplication File System [C]//6th USENIX Conference on File and Storage Technologies, San Jose, USA, 2008. DOI: 10.1126/science.1164390 |
| [2] | LILLIBRIDGE M, ESHGHI K, BHAGWAT D, et al. Sparse Indexing: Large Scale, Inline Deduplication Using Sampling and Locality [C]//7th USENIX Conference on File and Storage Technologies, San Francisco, USA, 2009. DOI: 10.1145/2187836.2187884 |
| [3] | DUBNICKI C, GRYZ L, HELDT L, et al. Hydrastor: A Scalable Secondary Storage [C]//7th USENIX Conference on File and Storage Technologies, San Francisco, USA, 2009 |
| [4] | FU M, FENG D, HUA Y, et al. Design Tradeoffs for Data Deduplication Performance in Backup Workloads [C]//13th USENIX Conference on File and Storage Technologies, Santa Clara, USA, 2015: 331-344 |
| [5] | MEYER D T, BOLOSKY W J . A Study of Practical Deduplication[J]. ACM Transactions on Storage, 2012,7(4):1-20. DOI: 10.1145/2078861.2078864 |
| [6] | IDC. The Digital Universe of Opportunities: Rich Data and the Increasing Value of the Internet of Things [EB/OL]. (2014-04). http://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm |
| [7] | WALLACE G, DOUGLIS F, QIAN H, et al. Characteristics of Backup Workloads in Production Systems [C]//10th USENIX Conference on File and Storage Technologies, San Jose, USA, 2012 |
| [8] | QUINLAN S, DORWARD S. Venti: A New Approach to Archival Storage [C]//USENIX Symposium on Networked Systems Design and Implementation, Monterey, USA, 2002: 89-102 |
| [9] | GUO F, EFSTATHOPOULOS P. Building a High-Performance Deduplication System [C]//USENIX Annual Technical Conference, Portland, USA, 2011 |
| [10] | PRESTON W C . Backup and Recovery[M]. Sebastopol, USA: O’Reilly Media, 2006 |
| [11] | FU M, FENG D, HUA Y, et al. Accelerating Restore and Garbage Collection in Deduplication-Based Backup Systems via Exploiting Historical Information [C]//USENIX Annual Technical Conference, Philadelphia, USA, 2014 |
| [12] | FU M. Destor: An Experimental Platform for Chunk-Level Data Deduplication [EB/OL]. (2014). |
| [13] | TARASOV V, MUDRANKIT A, BUIK W, et al. Generating Realistic Datasets for Deduplication Analysis [C]//USENIX Annual Technical Conference, Boston, USA, 2012 |
| [14] | BIGGAR H . Experiencing Data De-Duplication: Improving Efficiency and Reducing Capacity Requirements[R]. The Enterprise Strategy Group, 2007 |
| [15] | ASARO T, BIGGAR H . Data De-Duplication and Disk-To-Disk Backup Systems: Technical and Business Considerations [R]. The Enterprise Strategy Group, 2007 |
| [16] | XIA W, JIANG H, FENG D, et al. A Comprehensive Study of the Past, Present, and Future of Data Deduplication[J]. Proceedings of the IEEE, 2016,104(9):1681-1710. DOI: 10.1109/JPROC.2016.2571298 |
| [17] | RABIN M O . Fingerprinting by Random Polynomials [R]. Center for Research in Computing Tech., Aiken Computation Laboratory, Univ., 1981 |
| [18] | KRUUS E, UNGUREANU C, DUBNICKI C. Bimodal Content Defined Chunking for Backup Streams [C]//8th USENIX Conference on File and Storage Technologies, San Jose, USA, 2010 |
| [19] | AGARWAL B, AKELLA A, ANAND A, et al. Endre: An End-System Redundancy Elimination Service for Enterprises [C]//7th USENIX Symposium on Networked Systems Design and Implementation, San Jose, USA, 2010 |
| [20] | ZHANG Y C, JIANG H, FENG D, et al. AE: An Asymmetric Extremum Content Defined Chunking Algorithm for Fast and Bandwidth-Efficient Data Deduplication [C]//IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 2015: 1337-1345. DOI: 10.1109/INFOCOM.2015.7218510 |
| [21] | BHAGWAT D, ESHGHI K, LONG D D E, et al. Extreme Binning: Scalable, Parallel Deduplication for Chunk-Based File Backup [C]//IEEE International Symposium on Modeling, Analysis & Simulation of Computer and Telecommunication Systems, London, UK, 2009: 1-9. DOI: 10.1109/MASCOT.2009.5366623 |
| [22] | XIA W, JIANG H, FENG , et al. Silo: A Similarity-Locality Based Near-Exact Deduplication Scheme with Low RAM Overhead and High Throughput [C]//USENIX Annual Technical Conference, Portland, USA, 2011 |
| [23] | KACZMARCZYK M, BARCZYNSKI M, KILIAN W, et al. Reducing Impact of Data Fragmentation Caused by In-Line Deduplication [C]//ACM SYSTOR, Haifa, Israel, 2012. DOI: 10.1145/2367589.2367600 |
| [24] | LILLIBRIDGE M, ESHGHI K, BHAGWAT D. Improving Restore Speed for Backup Systems that Use Inline Chunk-Based Deduplication [C]//11th USENIX Conference on File and Storage Technologies, San Jose, USA, 2013. DOI: 10.1145/2385603.2385607 |
| [25] | PARK D, FAN Z Q, NAM Y J, et al. A Lookahead Read Cache: Improving Read Performance for Deduplication Backup Storage[J]. Journal of Computer Science and Technology, 2017,32(1):26-40. DOI: 10.1007/s11390-017-1680-8 |
| [26] | SRINIVASAN K, BISSON T, GOODSON G, et al. IDedup: Latency-Aware, Inline Data Deduplication for Primary Storage [C]//10th USENIX Conference on File and Storage Technologies, San Jose, USA, 2012: 299-312. DOI: 10.1111/j.1360-0443.2007.01823.x |
| [27] | NG C-H, LEE P P. Revdedup: A Reverse Deduplication Storage System Optimized for Reads to Latest Backups [C]//ACM Asia-Pacific Workshop on Systems, Singapore, Singapore, 2013. DOI: 10.1145/2500727.2500731 |
| [28] | MAO B, JIANG H, WU S Z, et al. SAR: SSD Assisted Restore Optimization for Deduplication-Based Storage Systems in the Cloud [C]//IEEE Seventh International Conference on Networking, Architecture, and Storage, Xiamen, China, 2012: 328-337. DOI: 10.1109/NAS.2012.48 |
| [29] | TAN Y, JIANG H, FENG D, TIAN L, YAN Z. Cabdedupe: A Causality-Based Deduplication Performance Booster for Cloud Backup Services [C]//IEEE International Parallel & Distributed Processing Symposium, Anchorage, USA, 2011. DOI: 10.1109/IPDPS.2011.76 |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

