ZTE Communications ›› 2017, Vol. 15 ›› Issue (4): 38-42.doi: 10.3969/j.issn.1673-5188.2017.04.005
• Special Topic • Previous Articles Next Articles
ZANG Qimeng1, GUO Song2
Received:2017-06-23
Online:2017-10-25
Published:2019-12-02
About author:ZANG Qimeng (zangqm.uoa@gmail.com) is a graduate student in the department of Computer Science and Engineering, The University of Aizu, Japan. His research interests mainly include big data, cloud computing and RFID system.|GUO Song (song.guo@polyu.edu.hk) received his Ph.D. in computer science from University of Ottawa, Canada. He is currently a full professor at Department of Computing, The Hong Kong Polytechnic University (PolyU), China. Prior to joining PolyU, he was a full professor with The University of Aizu, Japan. His research interests are mainly in the areas of cloud and green computing, big data, wireless networks, and cyber-physical systems. He has published over 300 conference and journal papers in these areas and received multiple best paper awards from IEEE/ACM conferences. His research has been sponsored by JSPS, JST, MIC, NSF, NSFC, and industrial companies. Dr. GUO has served as an editor of several journals, including IEEE TPDS, IEEE TETC, IEEE TGCN, IEEE Communications Magazine, and Wireless Networks. He has been actively participating in international conferences serving as general chairs and TPC chairs. He is a senior member of IEEE, a senior member of ACM, and an IEEE Communications Society Distinguished Lecturer.
ZANG Qimeng, GUO Song. Online Shuffling with Task Duplication in Cloud[J]. ZTE Communications, 2017, 15(4): 38-42.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
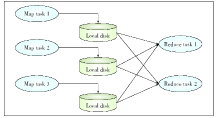
Figure 1.
The MapReduce model."
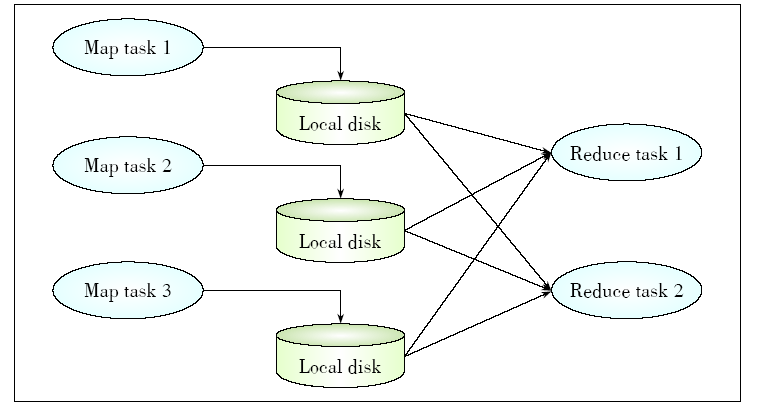
Figure 2.
Non-overlapping data block transmitting."
Table 1
Symbols and variables"
| Notations | Description |
|---|---|
| M | A set of machines to generate intermediate data |
| R | A set of machines to receive intermediate data |
| Data volume of an intermediate record produced by machine x | |
| The traffic cost from machine x ∈ M to machine y ∈ R | |
| The cost caused by communication with the controller | |
| The total cost of transmitting group i | |
| The delay cost of group i | |
| The distance between two machines x and y |
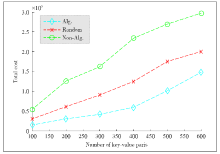
Figure 3.
Total cost vs. the number of key-value pairs."
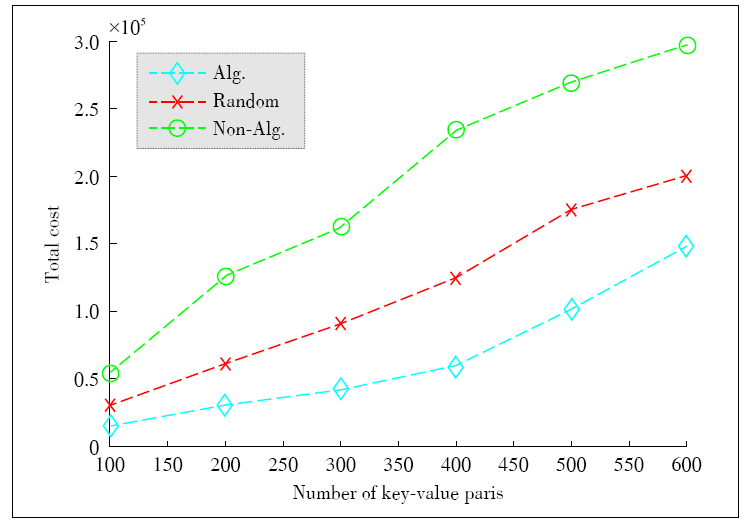
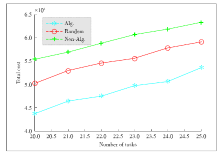
Figure 4.
Total cost vs. the number of tasks."
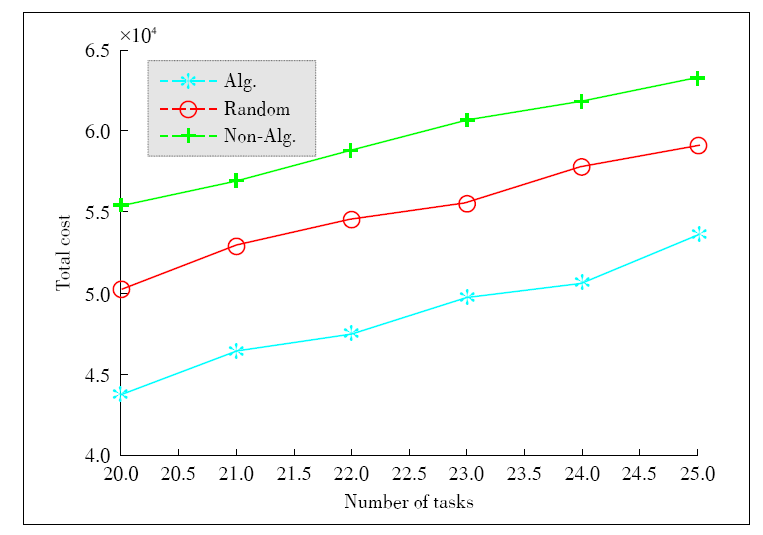
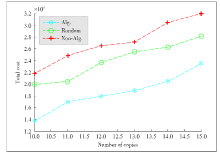
Figure 5.
Total cost vs. the number of task duplications."
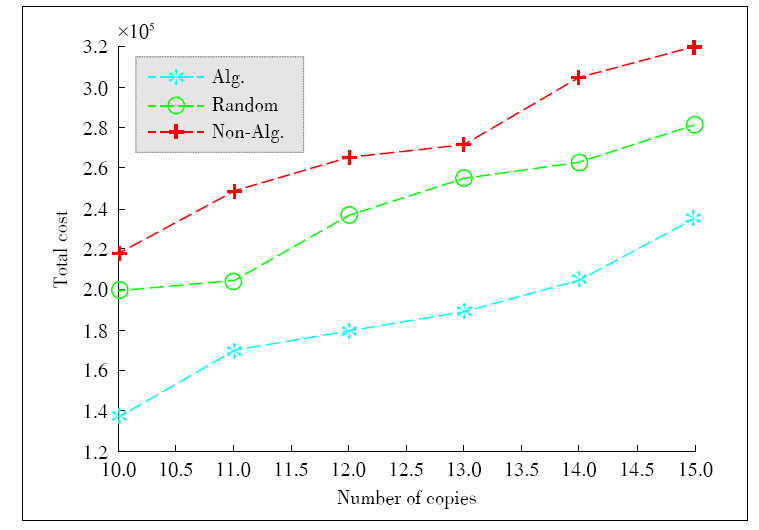
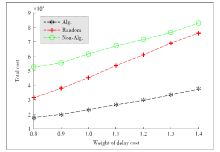
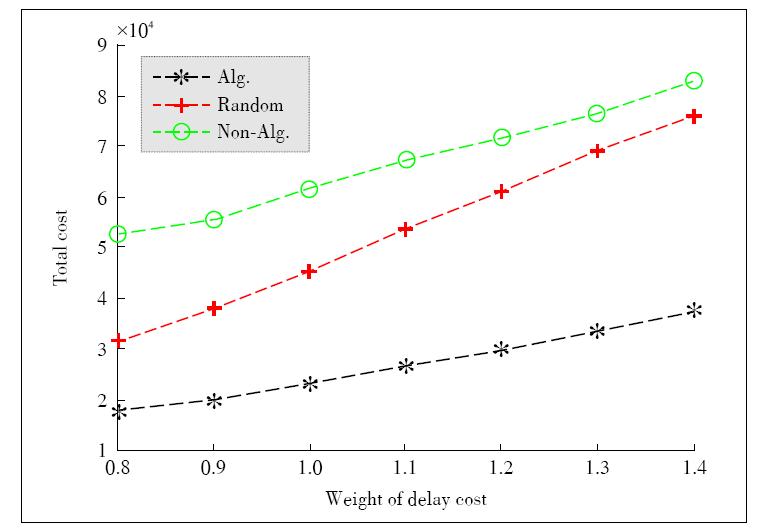
Figure 6.
Total cost vs. weight of delay."
| [1] | S. Zou, X. Wen, K. Chen , et al., “Virtualknotter: online virtual machine shuffling for congestion resolving in virtualized datacenter,” Computer Networks, vol. 67, pp. 141-153, 2014. doi: 10.1109/ICDCS.2012.25. |
| [2] | G. Ananthanarayanan, A. Ghodsi, S. Shenker, I. Stoica , “Effective straggler mitigation: attack of the clones,” in 10th USENIX Symposium on Networked Systems Design and Implementation (NSDI’13), Lombard,USA, 2013, pp. 185-198. |
| [3] | G. Ananthanarayanan, M. C.-C Hung, X. Ren ., et al., “Grass: trimming stragglers in approximation analytics,” in 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI’14), Seattle,USA, 2014, pp. 289-302. |
| [4] | C.-Y Hong, S. Kandula, R. Mahajan , et al., “Achieving high utilization with software-driven WAN,” in SIGCOMM’13, Hong Kong, China, 2013, pp. 15-26. doi: 10.1145/2534169.2486012. |
| [5] | J. Dean and S. Ghemawat , “MapReduce: simplified data processing on large clusters,” in Proc. 6th USENIX Symposium on Operating Systems Design and Implementation (OSDI’04), San Francisco, USA, 2004, vol. 6, pp. 10-10. |
| [6] | The Apache Software Foundation. (2017, Mar. 29). Apache Hadoop [Online]. Available: |
| [7] | T. Condie, N. Conway, P. Alvaro , et al., “Mapreduce online,” in Proc.7th USENIX Conference on Networked Systems Design and Implementation (NSDI’10), San Jose,USA, 2010, pp. 21-21. |
| [8] | G. D. Ghare and S. T. Leutenegger , “Improving speed up and response times by replicating parallel programs on a snow,” in 11th International Workshop on Job Scheduling Strategies for Parallel Processing (JSSPP), Cambridge, USA, 2005, pp. 264-287. |
| [9] | M. Zaharia, A. Konwinski, A. D. Joseph, R. Katz, I. Stoica , “Improving MapReduce performance in heterogeneous environments,” in Proc. 8th USENIX Symposium on Operating Systems Design and Implementation (OSDI’08), San Diego, USA, 2008, pp. 29-42. |
| [10] | M. Isard, M. Budiu, Y. Yu, A. Birrell, D. Fetterly , “Dryad: distributed data-parallel programs from sequential building blocks,” in Proc. 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems, Lisbon,Portugal, 2007, pp. 59-72. doi: 10.1145/1272996.1273005. |
| [11] | G. Ananthanarayanan, S. Kandula, A. Greenberg , et al., “Reining in the outliers in map- reduce clusters using mantri,” in Proc. 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI’10), Vancouver, Canada, 2010, pp. 265-278. |
| [12] | A. Baratloo, M. Karaul, Z. M. Kedem, P. Wijckoff , “Char- lotte: metacomputing on the Web,” Future Generation Computer Systems, vol. 15, no.5-6, pp. 559-570, 1999. |
| [13] | M. C. Rinard and P. C. Diniz , “Commutativity analysis: A new analysis framework for parallelizing compilers,” in Proc. ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), Philadelphia,USA, 1996, pp. 54-67. |
| [14] | Q. Zang, H. Y. Chan, P. Li, S. Guo , “Software-defined data shuffling for big data jobs with task duplication,” in 45th International Conference on Parallel Processing Workshops (ICPPW), Philadelphia, USA, 2016, pp. 403-407. doi: 10.1109/ICPPW.2016.62. |
| [1] | SHI Zongsheng, JIANG Jian, JING Sizhe, LI Qiyuan, MA Xiaoran. Application of Industrial Internet Identifier in Optical Fiber Industrial Chain [J]. ZTE Communications, 2020, 18(1): 66-72. |
| [2] | NI Dong, LI Hui, JI Yuefeng, LI Hongbiao, ZHU Yinan. A Service-Based Intelligent Time-Domain and Spectral-Domain Flow Aggregation in IP-over-EON Based on SDON [J]. ZTE Communications, 2019, 17(3): 56-62. |
| [3] | YE Dezhong, LV Haibing, GAO Yun, BAO Qiuxia, CHEN Mingzi. Novel Real-Time System for Traffic Flow Classification and Prediction [J]. ZTE Communications, 2019, 17(2): 10-18. |
| [4] | WANG Shihao, ZHUO Qinzheng, YAN Han, LI Qianmu, QI Yong. A Network Traffic Prediction Method Based on LSTM [J]. ZTE Communications, 2019, 17(2): 19-25. |
| [5] | HU Baiqing, WANG Wenjie, Chi Harold Liu. Open Source Initiatives for Big Data Governance and Security: A Survey [J]. ZTE Communications, 2018, 16(2): 55-66. |
| [6] | REN Fuji, Kazuyuki Matsumoto. Emotion Analysis on Social Big Data [J]. ZTE Communications, 2017, 15(S2): 30-37. |
| [7] | MENG Ziqian, GUAN Zhi, WU Zhengang, LI Anran, CHEN Zhong. Security Enhanced Internet of Vehicles with Cloud-Fog-Dew Computing [J]. ZTE Communications, 2017, 15(S2): 47-51. |
| [8] | CHEN Aiguo, WU Huaigu, TIAN Ling, LUO Guangchun. HCOS: A Unified Model and Architecture for Cloud Operating System [J]. ZTE Communications, 2017, 15(4): 23-29. |
| [9] | ZHOU Yuezhi, ZHANG Di, ZHANG Yaoxue. A Transparent and User-Centric Approach to Unify Resource Management and Code Scheduling of Local, Edge, and Cloud [J]. ZTE Communications, 2017, 15(4): 3-11. |
| [10] | WANG Yingwei, Karolj Skala, Andy Rindos, Marjan Gusev, YANG Shuhui, PAN Yi. Dew Computing and Transition of Internet Computing Paradigms [J]. ZTE Communications, 2017, 15(4): 30-37. |
| [11] | LI Bing, ZHANG Yunyong, XU Lei. An MEC and NFV Integrated Network Architecture [J]. ZTE Communications, 2017, 15(2): 19-25. |
| [12] | TU Yaofeng, DONG Zhenjiang, YANG Hongzhang. Key Technologies and Application of Edge Computing [J]. ZTE Communications, 2017, 15(2): 26-34. |
| [13] | WU Chunming, LIU Qianjun, LI Yuwei, CHENG Qiumei, ZHOU Haifeng. A Survey on Cloud Security [J]. ZTE Communications, 2017, 15(2): 42-47. |
| [14] | Nargis Khan, Jelena Mišić, and Vojislav B. Mišić. On Coexistence of Vehicular Overlay Network and H2H Terminals on PRACH in LTE [J]. ZTE Communications, 2016, 14(3): 3-12. |
| [15] | Smitha Shivshankar and Abbas Jamalipour. A Cloud Computing Perspective for Distributed Routing in Vehicular Environments [J]. ZTE Communications, 2016, 14(3): 36-44. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

