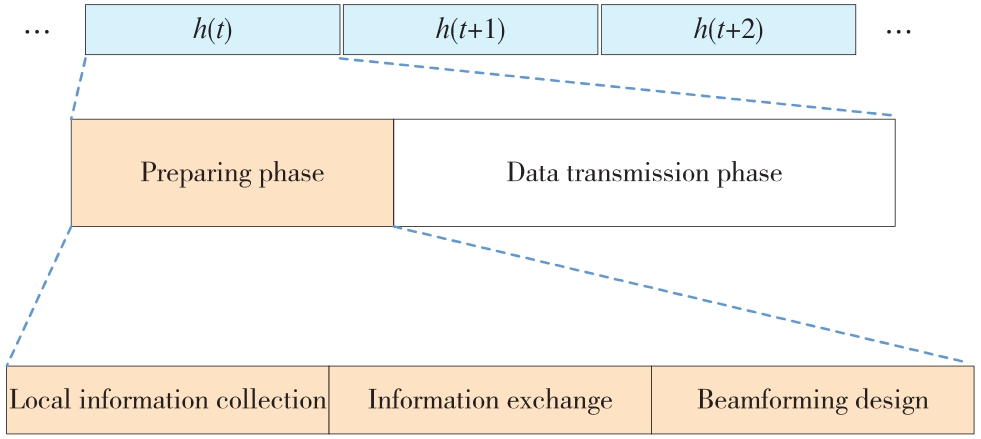
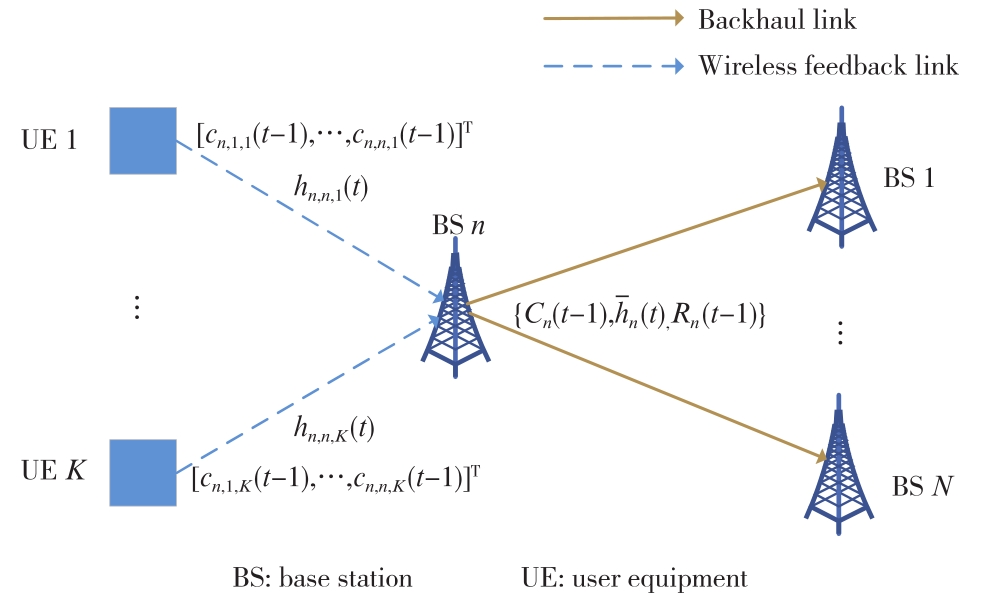
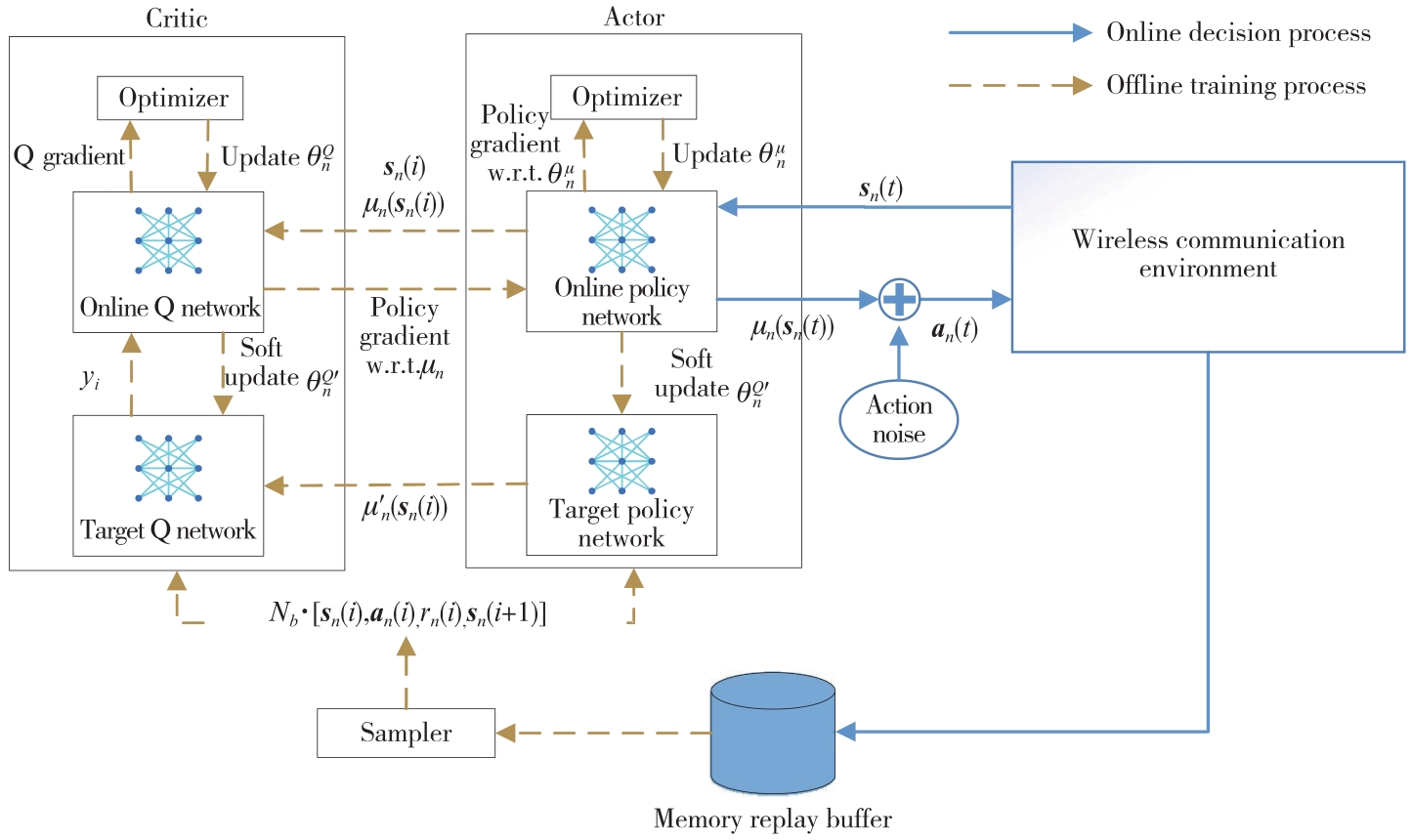
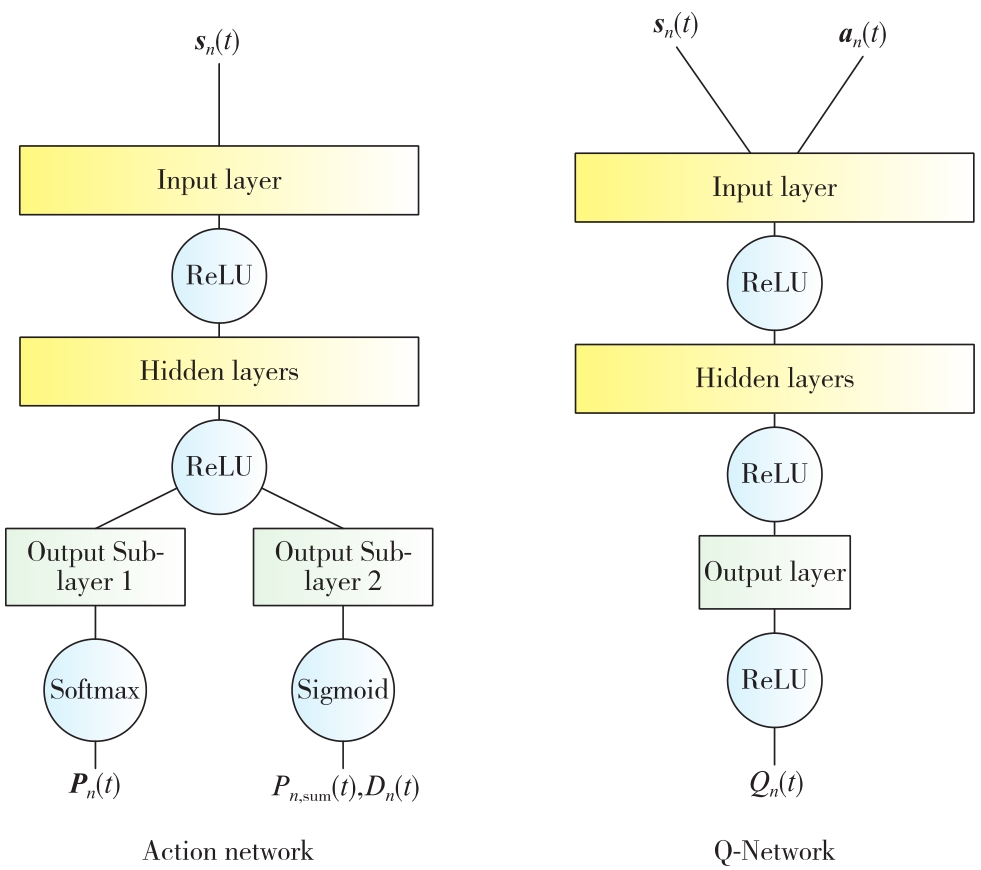
| 1 |
SOMEKH O, SIMEONE O, BAR-NESS Y, et al. Cooperative multicell zero-forcing beamforming in cellular downlink channels [J]. IEEE transactions on information theory, 2009, 55(7): 3206–3219. DOI: 10.1109/TIT.2009.2021371
DOI
|
| 2 |
HUANG Y M, ZHENG G, BENGTSSON M, et al. Distributed multicell beamforming with limited intercell coordination [J]. IEEE transactions on signal processing, 2011, 59(2): 728–738. DOI: 10.1109/TSP.2010.2089621
DOI
|
| 3 |
SHEN K M, YU W. Fractional programming for communication systems—part I: power control and beamforming [J]. IEEE transactions on signal processing, 2018, 66(10): 2616–2630. DOI: 10.1109/TSP.2018.2812733
DOI
|
| 4 |
ZHANG R, CUI S G. Cooperative interference management with MISO beamforming [J]. IEEE transactions on signal processing, 2010, 58(10): 5450–5458. DOI: 10.1109/TSP.2010.2056685
DOI
|
| 5 |
BJÖRNSON E, ZAKHOUR R, GESBERT D, et al. Cooperative multicell precoding: rate region characterization and distributed strategies with instantaneous and statistical CSI [J]. IEEE transactions on signal processing, 2010, 58(8): 4298–4310. DOI: 10.1109/TSP.2010.2049996
DOI
|
| 6 |
PARK S H, PARK H, LEE I. Distributed beamforming techniques for weighted sum-rate maximization in MISO interference channels [J]. IEEE communications letters, 2010, 14(12): 1131–1133. DOI: 10.1109/LCOMM.2010.12.101635
DOI
|
| 7 |
GE J G, LIANG Y C, JOUNG J, et al. Deep reinforcement learning for distributed dynamic MISO downlink-beamforming coordination [J]. IEEE transactions on communications, 2020, 68(10): 6070–6085. DOI: 10.1109/TCOMM.2020.3004524
DOI
|
| 8 |
KHAN A A, ADVE R S. Centralized and distributed deep reinforcement learning methods for downlink sum-rate optimization [J]. IEEE transactions on wireless communications, 2020, 19(12): 8410–8426. DOI: 10.1109/TWC.2020.3022705
DOI
|
| 9 |
INDYK P, MOTWANI R. Approximate nearest neighbors: towards removing the curse of dimensionality [C]//The Thirtieth Annual ACM Symposium on Theory of Computing. STOC, 1998: 604–613
|
| 10 |
YING D W, VOOK F W, THOMAS T A, et al. Kronecker product correlation model and limited feedback codebook design in a 3D channel model [C]//Proceedings of 2014 IEEE International Conference on Communications. IEEE, 2014: 5865–5870. DOI: 10.1109/ICC.2014.6884258
DOI
|
| 11 |
DONG M, TONG L, SADLER B M. Optimal insertion of pilot symbols for transmissions over time-varying flat fading channels [J]. IEEE transactions on signal processing, 2004, 52(5): 1403–1418. DOI: 10.1109/TSP.2004.826182
DOI
|
| 12 |
SCHUBERT M, BOCHE H. Solution of the multiuser downlink beamforming problem with individual SINR constraints [J]. IEEE transactions on vehicular technology, 2004, 53(1): 18–28. DOI: 10.1109/TVT.2003.819629
DOI
|
| 13 |
CHRISTENSEN S S, AGARWAL R, DE CARVALHO E, et al. Weighted sum-rate maximization using weighted MMSE for MIMO-BC beamforming design [J]. IEEE transactions on wireless communications, 2008, 7(12): 4792–4799. DOI: 10.1109/T-WC.2008.070851
DOI
|
| 14 |
JORSWIECK E A, LARSSON E G, DANEV D. Complete characterization of the Pareto boundary for the MISO interference channel [J]. IEEE transactions on signal processing, 2008, 56(10): 5292–5296. DOI: 10.1109/TSP.2008.928095
DOI
|
| 15 |
LIM Y G, CHAE C B, CAIRE G. Performance analysis of massive MIMO for cell-boundary users [J]. IEEE transactions on wireless communications, 2015, 14(12): 6827–6842. DOI: 10.1109/TWC.2015.2460751
DOI
|
| 16 |
MENG F, CHEN P, WU L N, et al. Power allocation in multi-user cellular networks: deep reinforcement learning approaches [J]. IEEE transactions on wireless communications, 2020, 19(10): 6255–6267. DOI: 10.1109/TWC.2020.3001736
DOI
|
| 17 |
HESTER T, VECERIK M, PIETQUIN O, et al. Deep Q-learning from demonstrations [EB/OL]. [2022-02-02]. . DOI: 10.1609/aaai.v32i1.11757
DOI
URL
|
| 18 |
DONG S K, CHEN J R, LIU Y, et al. Reinforcement learning from algorithm model to industry innovation : a foundation stone of future artificial intelligence [J]. ZTE communications, 2019, 17(3): 31–41. DOI: 10.12142/Z TECOM.201903006
DOI
|
| 19 |
SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms [C]//Proceeding of International Conference on Machine Learning. ICML, 2014: 387–395
|
 ), TAN Wanlong1, RUI Hua2,3, LIN Wei2,3
), TAN Wanlong1, RUI Hua2,3, LIN Wei2,3