ZTE Communications ›› 2017, Vol. 15 ›› Issue (S2): 23-29.DOI: 10.3969/j.issn.1673-5188.2017.S2.004
-
收稿日期:2017-08-15出版日期:2017-12-25发布日期:2020-04-16
Multimodal Emotion Recognition with Transfer Learning of Deep Neural Network
HUANG Jian1,2, LI Ya1, TAO Jianhua1,2,3, YI Jiangyan1,2
- 1. National Laboratory of Pattern Recognition, Beijing 100190, China
2. School of Artificial Intelligence, University of Chinese Academy of Science, Beijing 100190, China
3. CAS Center for Excellence in Brain Science and Intelligence Technology, Institute of Automation, Chinese Academy of Sciences, Beijing 100190, China
-
Received:2017-08-15Online:2017-12-25Published:2020-04-16 -
About author:HUANG Jian (jian.huang@nlpr.ia.ac.cn) is a Ph.D. candidate at the National Laboratory of Pattern Recognition (NLPR), Institute of Automation, Chinese Academy of Sciences (CASIA), China. His research interest covers affective computing, deep learning, and multimodal emotion recognition.|LI Ya (yli@nlpr.ia.ac.cn) received the B.E. degree from University of Science and Technology of China (USTC), China in 2007, and Ph.D. degree from the NLPR, CASIA in 2012. From November 2012 to December 2012, she was a visiting scholar in the University of Tokyo, Japan. From May 2014 to September 2014, she was a research fellow with Trinity College Dublin, Ireland. She is currently an associate professor with the NLPR, CASIA. She won several best student papers in INTERSPEECH, NCMMSC, etc. Her general interests include speech recognition and synthesis, affective computing, human computer interaction, and natural language processing.|TAO Jianhua (jhtao@nlpr.ia.ac.cn) received his Ph.D. from Tsinghua University, China in 2001 and MS. from Nanjing University, China in 1996. He is currently a professor with the NLPR, CASIA. His current research interests include speech synthesis and coding methods, human computer interaction, multimedia information processing, and pattern recognition. He has published more than eighty papers on major journals and proceedings including IEEE Transactions on ASLP, and got several awards from the important conferences, such as Eurospeech, NCMMSC, etc. He serves as the chair or program committee member for several major conferences, including ICPR, ACII, ICMI, ISCSLP, NCMMSC, etc. He also serves as the steering committee member for IEEE Transactions on Affective Computing, an associate editor for Journal on Multimodal User Interface and International Journal on Synthetic Emotions, and Deputy Editor-in-chief for Chinese Journal of Phonetics.|YI Jiangyan (jiangyan.yi@nlpr.ia.ac.cn) is a Ph.D. candidate at the NLPR, CASIA, China. Her research interest covers deep learning, speech recognition, and transfer learning. -
Supported by:This work is is supported by the National Natural Science Foundation of China (NSFC)(61425017);This work is is supported by the National Natural Science Foundation of China (NSFC)(61773379);the National Key Research & Development Plan of China(2017YFB1002804);the Major Program for the National Social Science Fund of China(13&ZD189)
引用本文
. [J]. ZTE Communications, 2017, 15(S2): 23-29.
HUANG Jian, LI Ya, TAO Jianhua, YI Jiangyan. Multimodal Emotion Recognition with Transfer Learning of Deep Neural Network[J]. ZTE Communications, 2017, 15(S2): 23-29.
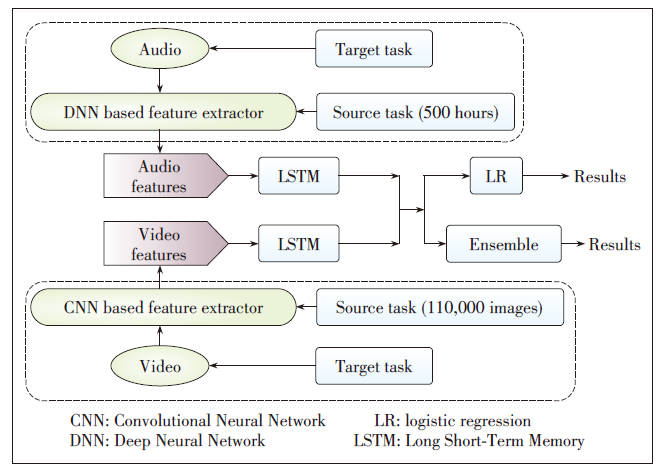
Figure 1. Framework of the proposed method. The audio features from the DNN feature extractor and video features from the CNN feature extractor are fed into LSTM, and then logistic regression and the ensemble method are utilized in decision level fusion.
| Category | Angry | Disgust | Fear | Happy | Sad | Surprise | Neutral |
|---|---|---|---|---|---|---|---|
| Number | 462 | 310 | 56 | 440 | 460 | 190 | 300 |
Table 1 Number of samples for seven emotional categories
| Category | Angry | Disgust | Fear | Happy | Sad | Surprise | Neutral |
|---|---|---|---|---|---|---|---|
| Number | 462 | 310 | 56 | 440 | 460 | 190 | 300 |

Figure 2. Different types of facial expression images.
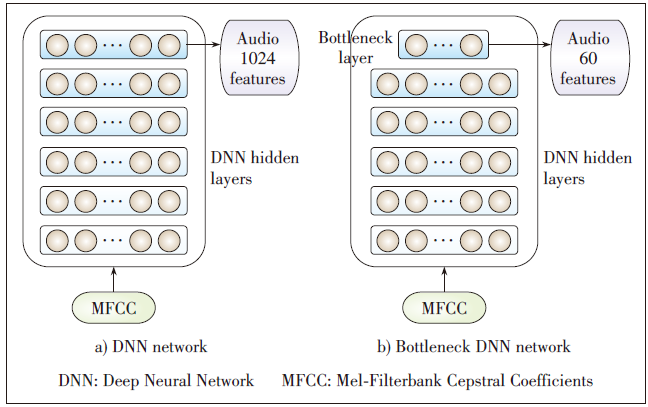
Figure 3. Diagram of audio features extraction.
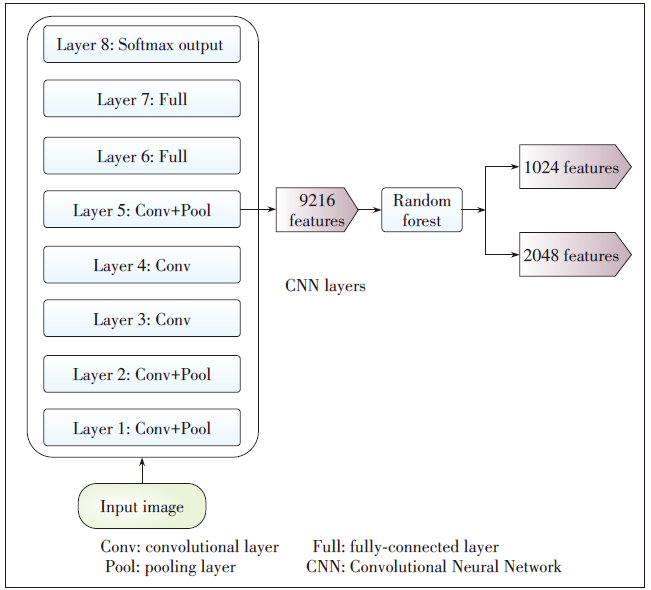
Figure 4. Diagram of visual features extraction.
| Features | Accuracy |
|---|---|
| Handcrafted audio features (147) | 0.31 |
| a60 | 0.40 |
| a1024 | 0.36 |
| v1024 | 0.45 |
| v2048 | 0.46 |
Table 2 Recognition accuracy for audio and video modalities
| Features | Accuracy |
|---|---|
| Handcrafted audio features (147) | 0.31 |
| a60 | 0.40 |
| a1024 | 0.36 |
| v1024 | 0.45 |
| v2048 | 0.46 |
| Accuracy | v1024 | v2048 | ||
|---|---|---|---|---|
| LR | Ensemble | LR | Ensemble | |
| a60 | 0.48 | 0.49 | 0.49 | 0.49 |
| a1024 | 0.47 | 0.47 | 0.47 | 0.48 |
Table 3 Recognition accuracies for multimodal decision level fusion (LR and the ensemble method)
| Accuracy | v1024 | v2048 | ||
|---|---|---|---|---|
| LR | Ensemble | LR | Ensemble | |
| a60 | 0.48 | 0.49 | 0.49 | 0.49 |
| a1024 | 0.47 | 0.47 | 0.47 | 0.48 |
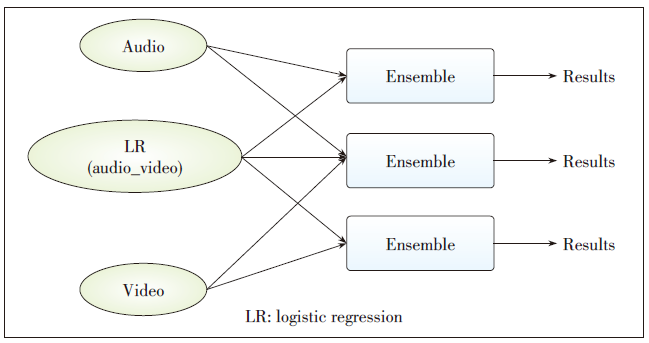
Figure 5. Fusion between the results of LR with corresponding audio and video results using the ensemble method.
| Accuracy | Audio | Video | Audio+Video |
|---|---|---|---|
| LR (a60_v1024) | 0.51 | 0.47 | 0.51 |
| LR (a60_v2048) | 0.51 | 0.46 | 0.49 |
| LR (a1024_v1024) | 0.47 | 0.48 | 0.48 |
| LR (a1024_v2048) | 0.49 | 0.45 | 0.46 |
Table 4 Recognition accuracy of fusion between the results of LR with corresponding audio and video results using the ensemble method
| Accuracy | Audio | Video | Audio+Video |
|---|---|---|---|
| LR (a60_v1024) | 0.51 | 0.47 | 0.51 |
| LR (a60_v2048) | 0.51 | 0.46 | 0.49 |
| LR (a1024_v1024) | 0.47 | 0.48 | 0.48 |
| LR (a1024_v2048) | 0.49 | 0.45 | 0.46 |
| Accuracy | Audio | Video |
|---|---|---|
| LR (a60_v1024) | 0.52 (0.086) | 0.48 (0.032) |
| LR (a60_v2048) | 0.51 (0.095) | 0.49 (0.032) |
| LR (a_1024_v1024) | 0.48 (0.113) | 0.48 (0.023) |
| LR (a1024_v2048) | 0.51 (0.111) | 0.47 (0.011) |
Table 5 Recognition accuracy using the ensemble method with prior knowledge
| Accuracy | Audio | Video |
|---|---|---|
| LR (a60_v1024) | 0.52 (0.086) | 0.48 (0.032) |
| LR (a60_v2048) | 0.51 (0.095) | 0.49 (0.032) |
| LR (a_1024_v1024) | 0.48 (0.113) | 0.48 (0.023) |
| LR (a1024_v2048) | 0.51 (0.111) | 0.47 (0.011) |
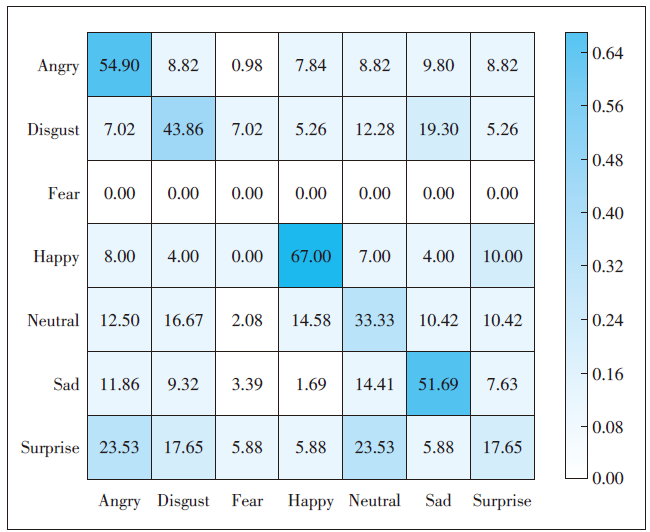
Figure 6. Confusion matrix of the best recognition accuracy using the ensemble method with prior knowledge (%).
| [1] | J. Tao and T. Tan , “Affective computing: A review,” in International Conference on Affective Computing and Intelligent Interaction, Beijing, China, Oct. 2005, pp. 981-995. doi: 10.1007/11573548_125. |
| [2] | J. A. Russell, J. A. Bachorowski, J. M. Fernández-Dols , “Facial and vocal expressions of emotion,” Annual Review of Psychology, Nov. 2003, pp. 329-349. doi: 10.1146/annurev.psych.54.101601.145102. |
| [3] | C. Busso, Z. Deng, S. Yildirim , et al., “Analysis of emotion recognition using facial expressions, speech and multimodal information,” in Proc. 6th International Conference on Multimodal Interfaces, State College, USA, Oct. 2004, pp. 205-211. doi: 10.1145/1027933.1027968. |
| [4] | Y. Li, L. Chao, Y. Liu , et al., “From simulated speech to natural speech, what are the robust features for emotion recognition?” in IEEE International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, Sept. 2015, pp. 368-373. doi: 10.1109/ACII.2015.7344597. |
| [5] | F. Eyben, K. R. Scherer, B. W. Schuller , et al., “The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing,” IEEE Transactions on Affective Computing, Jan. 2015, pp. 190-202. doi: 10.1109/TAFFC.2015.2457417. |
| [6] | B. Schuller, S. Steidl, A. Batliner , et al., “The INTERSPEECH 2014 computational paralinguistics challenge: cognitive & physical load,” in 15th Annual Conference of the International Speech Communication Association, Singapore, Singapore, Sept. 2014, pp. 427-431. |
| [7] | F. Ringeval, B. Schuller, M. Valstar , et al., “Av+ ec 2015: the first affect recognition challenge bridging across audio, video, and physiological data,” in Proc. 5th International Workshop on Audio/Visual Emotion Challenge, Brisbane, Australia, Jan. 2015, pp. 3-8. doi: 10.1145/2808196.2811642. |
| [8] | M. Valstar, J. Gratch, B. Schuller , et al., “AVEC 2016-depression, mood, and emotion recognition workshop and challenge,” in 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, Oct. 2016, pp. 1483-1484. doi: 10.1145/2988257.2988258. |
| [9] | X. Xia, L. Guo, D. Jiang , et al., “Audio visual recognition of spontaneous emotions in-the-wild,” in Chinese Conference on Pattern Recognition, Chengdu, China, Nov. 2016, pp. 692-706. doi: 10.1007/978-981-10-3005-5_57. |
| [10] | J. Wu, Z. Lin, H. Zha , “Multiple models fusion for emotion recognition in the wild,” in Proc. 2015 ACM on International Conference on Multimodal Interaction, Seattle, USA, Nov. 2015, pp. 475-481. doi: 10.1145/2818346.2830582. |
| [11] | B. Sun, L. Li, G. Zhou , et al, “Combining multimodal features within a fusion network for emotion recognition in the wild,” in Proc. 2015 ACM on International Conference on Multimodal Interaction, Seattle, USA, Nov. 2015, pp. 497-502. doi: 10.1145/2818346.2830586. |
| [12] | K. Han, D. Yu, I. Tashev , et al., “Speech emotion recognition using deep neural network and extreme learning machine,” in 14th Annual Conference of the International Speech Communication Association, Malaysia, Singapore, Sept. 2014, pp. 223-227. |
| [13] | Q. Mao, M. Dong, Z. Huang , et al., “Learning salient features for speech emotion recognition using convolutional neural networks,” IEEE Transactions on Multimedia, vol. 16, no. 8, pp. 2203-2213, Dec. 2014. doi: 10.1109/TMM.2014.2360798. |
| [14] | K. S. Ebrahimi, V. Michalski, K. Konda , et al., “Recurrent neural networks for emotion recognition in video,” in Proc. 2015 ACM on International Conference on Multimodal Interaction, Seattle, USA, Nov. 2015, pp. 467-474. doi: 10.1145/2818346.2830596. |
| [15] | B. K. Kim, H. Lee, J. Roh , et al., “Hierarchical committee of deep cnns with exponentially-weighted decision fusion for static facial expression recognition,” in Proc. 2015 ACM on International Conference on Multimodal Interaction, Seattle, USA, Nov. 2015, pp. 427-434. doi: 10.1145/2818346.2830590. |
| [16] | J. Lu, V. Behbood, P. Hao , et al., “Transfer learning using computational intelligence: a survey,” Knowledge-Based Systems, vol. 80, pp. 14-23, May 2015, pp. 14-23. doi: 10.1016/j.knosys.2015.01.010. |
| [17] | Y. Huang, M. Hu, X. Yu , et al., “Transfer Learning of Deep Neural Network for Speech Emotion Recognition,” in Chinese Conference on Pattern Recognition, Chengdu, China, Nov. 2016, pp. 721-729. doi: 10.1007/978-981-10-3005-5_59. |
| [18] | H. W. Ng, V. D. Nguyen, V. Vonikakis , et al., “Deep learning for emotion recognition on small datasets using transfer learning,” in Proc. 2015 ACM on International Conference on Multimodal Interaction, Seattle, USA, Nov. 2015, pp. 443-449. doi: 10.1145/2818346.2830593. |
| [19] | H. Gunes , “Automatic, dimensional and continuous emotion recognition,” International Journal of Synthetic Emotions, vol. 1, no. 1, pp. 68-99, Jan.-Jun. 2010. doi: 10.4018/jse.2010101605. |
| [20] | Z. Yu and C. Zhang , “Image based static facial expression recognition with multiple deep network learning,” in Proc. 2015 ACM on International Conference on Multimodal Interaction, Seattle, USA, Nov. 2015, pp. 435-442. doi: 10.1145/2818346.2830595. |
| [21] | F. Sebastiani , “Machine learning in automated text categorization,” ACM Computing Surveys (CSUR), vol. 34, no. 1, pp. 1-47, Mar. 2002. doi: 10.1145/505282.505283. |
| [22] | Y. Li, J. Tao, L. Chao , et al., “CHEAVD: a Chinese natural emotional audio-visual database,” Journal of Ambient Intelligence and Humanized Computing, vol. 8, no. 6, pp. 1-12, Nov. 2017. doi: 10.1007/s12652-016-0406-z. |
| [23] | F. Grézl, E. Egorova, M. Karafiát , “Further investigation into multilingual training and adaptation of stacked bottle-neck neural network structure,” in Spoken Language Technology Workshop (SLT), South Lake Tahoe, USA, Dec. 2014, pp. 48-53. doi: 10.1109/SLT.2014.7078548. |
| [24] | X. Zhang, X.-J. Wang, and H.-Y. Shum , “Finding celebrities in billions of web images,” IEEE Transactions on Multimedia, vol. 14, no. 4, Aug. 2012. doi: 10.1109/TMM.2012.2186121. |
| [25] | H.-W. Ng and S. Winkler , “A data-driven approach to cleaning large face datasets,” in Proc. IEEE International Conference on Image Processing (ICIP), Paris, France, Oct. 2014. doi: 10.1109/ICIP.2014.7025068. |
| [26] | X. Xiong and F. D. Torre , “Supervised descent method and its applications to face alignment,” in Proc. IEEE Conference on Computer Vision And Pattern Recognition, Portland, OR, USA, Jun. 2013, pp. 532-539. doi: 10.1109/CVPR.2013.75. |
| No related articles found! |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||