ZTE Communications ›› 2019, Vol. 17 ›› Issue (2): 26-37.DOI: 10.12142/ZTECOM.201902005
-
收稿日期:2018-03-13出版日期:2019-06-11发布日期:2019-11-14
Potential Off-Grid User Prediction System Based on Spark
LI Xuebing1,3, SUN Ying1,2, ZHUANG Fuzhen1,2, HE Jia1,2, ZHANG Zhao1,2, ZHU Shijun4, HE Qing1,2
- 1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China
2. University of Chinese Academy of Sciences, Beijing 100049, China
3. College of Information Science and Engineering, Yanshan University, Qinhuangdao, Hebei 066004, China
4. ZTE Corporation, Shenzhen, Guangdong 518057, China
-
Received:2018-03-13Online:2019-06-11Published:2019-11-14 -
About author:LI Xuebing received the M.S. degree from the College of Information Science and Engineering, Yanshan University, China. His research interests include machine learning and data mining. He is currently a recommended system engineer at Baidu|SUN Ying is a master candidate at the Institute of Computing Technology, Chinese Academy of Sciences, China. She received the B.S. degree from Beijing Institute of Technology, China in 2017. Her research interests include machine learning and data mining. She has published two research papers in SIGKDD|ZHUANG Fuzhen (zhuangfuzhen@ict.ac.cn ) received the B.S. degree in computer science from Chongqing University, China in 2006, and the Ph.D. degree in computer software and theory from the University of Chinese Academy of Sciences, China in 2011. He is currently an associate professor at the Institute of Computing Technology, Chinese Academy of Sciences, China. His research interests include machine learning, data mining, transfer learning, multi-task learning and recommendation systems. He has published around 60 papers in various journals and conferences, such as IEEE Transactions on Knowledge and Data Engineering, IEEE Transactions on Cybernetics, IEEE Transactions on Neural Network and Learning System, KDD, IJCAI, AAAI, ICDE, and WWW|HE Jia is a Ph.D. candidate at the Institute of Computing Technology, Chinese Academy of Sciences, China. Her research interests include machine learning, Bayesian nonparametric learning, and multi-view learning. She has published several papers in some relevant research conferences, such as IJCAI, ICDM, ECML, and CIKM|ZHANG Zhao is a Ph.D. candidate in the Institute of Computing Technology, Chinese Academy of Sciences, China. He received the B.S. degree from Beijing Institute of Technology, China in 2015. His research interests include machine learning, data mining, and relational learning. He has published several papers in some relevant research conferences and journals, such as EMNLP, CIKM, and information systems|ZHU Shijun received the B.E. degree in management science and engineering from University of Science and Technology of China (USTC) in 2003. Working with the Wireless Big Data R&D Center of ZTE Corporation, he is responsible for the development of smart optimization and planning sytem of wireless networks|HE Qing is a professor at the Institute of Computing Technology, Chinese Academy of Science (CAS), and he is also a professor at University of Chinese Academy of Sciences, China. He received the B.S. degree from Hebei Normal University, China in 1985, and the M.S. degree from Zhengzhou University, China in 1987, both in mathematics. He received the Ph.D. degree in fuzzy mathematics and artificial intelligence in 2000 from Beijing Normal University, China. He was with Hebei University of Science and Technology from 1987 to 1997. He is currently a doctoral tutor at the Institute of Computing and Technology, CAS. His interests include data mining, machine learning, classification, and fuzzy clustering -
Supported by:This work is supported by ZTE Industry-Academia-Research Cooperation, the National Key Research and Development Program of China under Grant No(2017YFB1002104);The National Natural Science Foundation of China under Grant Nos(U1836206);The National Natural Science Foundation of China under Grant Nos(U1811461);The National Natural Science Foundation of China under Grant Nos(61773361);The Project of Youth Innovation Promotion Association CAS under Grant No(2017146)
引用本文
. [J]. ZTE Communications, 2019, 17(2): 26-37.
LI Xuebing, SUN Ying, ZHUANG Fuzhen, HE Jia, ZHANG Zhao, ZHU Shijun, HE Qing. Potential Off-Grid User Prediction System Based on Spark[J]. ZTE Communications, 2019, 17(2): 26-37.

Figure 1. Spark Ecosystem.
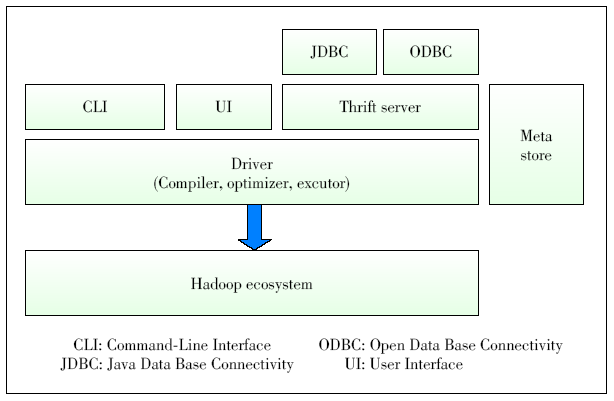
Figure 2. Hive architecture.
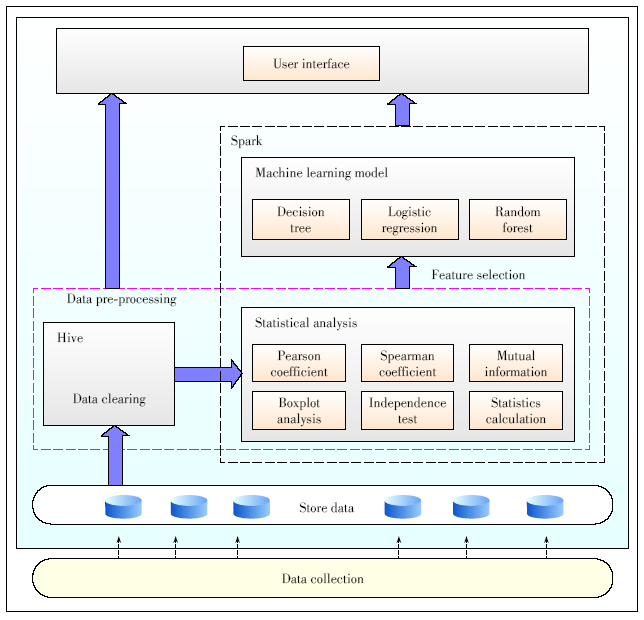
Figure 3. Architecture of the potential off-grid user prediction system based on Spark.
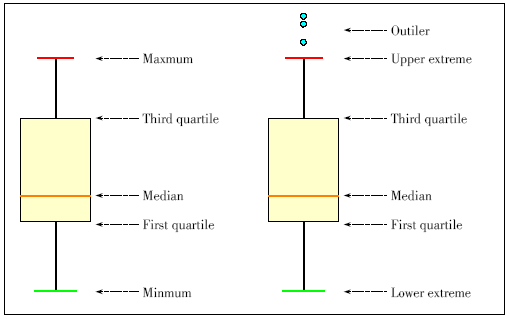
Figure 4. Two kinds of box plots.

Figure 5. Spark program flowchart.

Figure 6. The unified modeling language (UML) class diagram of the proposed potential off-grid user prediction system.
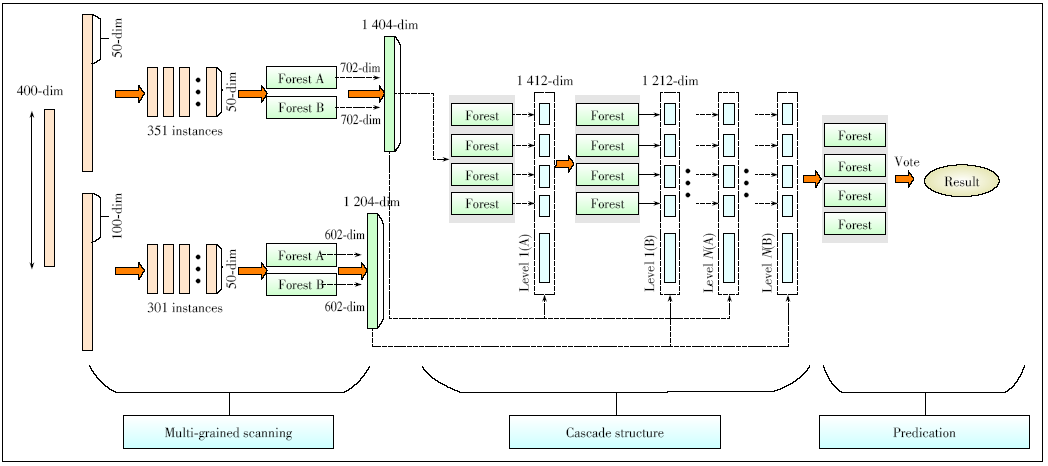
Figure 7. The gcForest architecture. Suppose there are two classes to predict, two sliding windows are used and original features are 400-dim.

Figure 8. The Parallel gcForest Algorithm.
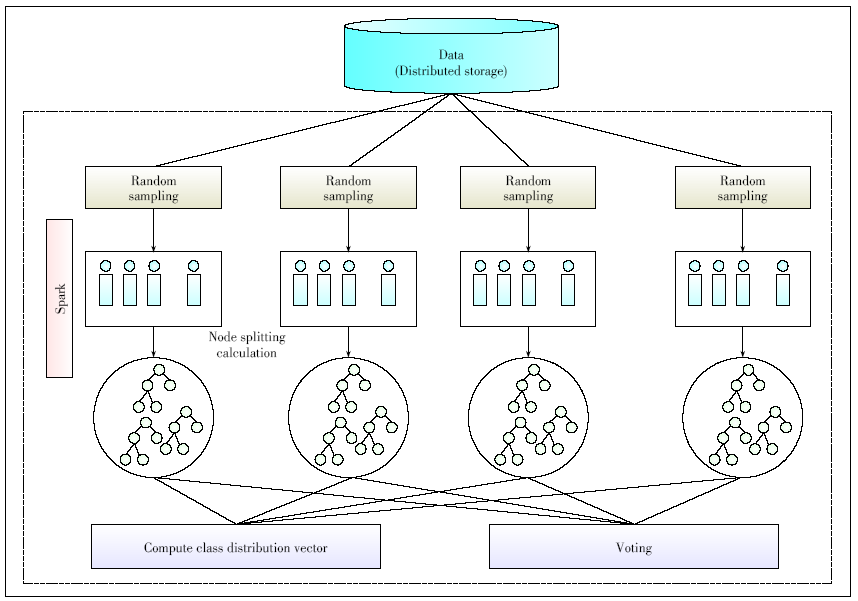
Figure 9. Structure of the parallel random forest algorithm.
| Dataset | Dimension | Training size | Test size |
|---|---|---|---|
| Churn management dateset | 21 | 2β000 | 1β033 |
| Telecom users dataset | 131 | 1 million+ | 1 million+ |
Table 1 Experiment data
| Dataset | Dimension | Training size | Test size |
|---|---|---|---|
| Churn management dateset | 21 | 2β000 | 1β033 |
| Telecom users dataset | 131 | 1 million+ | 1 million+ |
| Feature | Meaning |
|---|---|
| Account_length | How long this person has been in this plan |
| International_plan | This person has international plan=1, otherwise plan=0 |
| Voice_mail_plan | This person has voice mail plan=1, otherwise plan=0 |
| Number_vmail_message | The number of voice mails |
Table 2 Features in the churn management dataset
| Feature | Meaning |
|---|---|
| Account_length | How long this person has been in this plan |
| International_plan | This person has international plan=1, otherwise plan=0 |
| Voice_mail_plan | This person has voice mail plan=1, otherwise plan=0 |
| Number_vmail_message | The number of voice mails |
| Feature | Meaning |
|---|---|
| LatestServiceTime | Last service time before collecting information |
| CallerCount | The number of calling in a month |
| DataDuration | Time spent in the data business in a month |
| SmsSendTimesChange | The number of SMS messages sent in a month |
Table 3 Some features in the Telecom users dataset
| Feature | Meaning |
|---|---|
| LatestServiceTime | Last service time before collecting information |
| CallerCount | The number of calling in a month |
| DataDuration | Time spent in the data business in a month |
| SmsSendTimesChange | The number of SMS messages sent in a month |
| Algorithm | Recall | Precision | Accuracy | F1 |
|---|---|---|---|---|
| Decision tree | 0.7907 | 1.0 | 0.9913 | 0.8831 |
| Logistic regression | 0.9535 | 0.4409 | 0.9477 | 0.6029 |
| Random forest | 0.7442 | 0.8205 | 0.9825 | 0.7805 |
| Parallel gcForest | 0.8140 | 0.8333 | 0.9855 | 0.8235 |
Table 4 Experimental results based on the churn management dataset
| Algorithm | Recall | Precision | Accuracy | F1 |
|---|---|---|---|---|
| Decision tree | 0.7907 | 1.0 | 0.9913 | 0.8831 |
| Logistic regression | 0.9535 | 0.4409 | 0.9477 | 0.6029 |
| Random forest | 0.7442 | 0.8205 | 0.9825 | 0.7805 |
| Parallel gcForest | 0.8140 | 0.8333 | 0.9855 | 0.8235 |
| Training data | Test data | Recall | Precision | Accuracy | F1 |
|---|---|---|---|---|---|
| September | October | 0.7895 | 0.6023 | 0.9233 | 0.6833 |
| September | April | 0.7186 | 0.6682 | 0.9173 | 0.6925 |
| October | September | 0.7147 | 0.6723 | 0.9197 | 0.6926 |
| October | April | 0.7239 | 0.5310 | 0.9331 | 0.6126 |
| April | September | 0.7545 | 0.5305 | 0.9330 | 0.6125 |
| April | October | 0.7844 | 0.6052 | 0.9238 | 0.6833 |
Table 5 Experimental results based on the Telecom user dataset
| Training data | Test data | Recall | Precision | Accuracy | F1 |
|---|---|---|---|---|---|
| September | October | 0.7895 | 0.6023 | 0.9233 | 0.6833 |
| September | April | 0.7186 | 0.6682 | 0.9173 | 0.6925 |
| October | September | 0.7147 | 0.6723 | 0.9197 | 0.6926 |
| October | April | 0.7239 | 0.5310 | 0.9331 | 0.6126 |
| April | September | 0.7545 | 0.5305 | 0.9330 | 0.6125 |
| April | October | 0.7844 | 0.6052 | 0.9238 | 0.6833 |
| [1] | WARD J S, BARKER A. Undefined by Data: a Survey of Big Data Definitions [EB/OL].( 2013). |
| [2] | HAN L X, ONG H Y . Parallel Data Intensive Applications Using MapReduce: A Data Mining Case Study in Biomedical Sciences[J]. Cluster Computing, 2015,18(1):403-418. DOI: 10.1007/s10586-014-0405-9 |
| [3] | LU P, DONG Z J, LUO S M , et al. A Parallel Platform for Web Text Mining[J]. ZTE Communications, 2013,11(3):56-61. DOI: 10.3969/j.issn.1673-5188.2013.03.010 |
| [4] | PAGANO F, PARODI G, ZUNINO R . Parallel Implementation of Associative Memories for Image Classification[J]. Parallel Computing, 1993,19(6):667-684. DOI: 10.1016/0167-8191(93)90014-c |
| [5] | CHU C-T, KIM S K, LIN Y-A, et al. Map-Reduce for Machine Learning on Multicore [C]//19th International Conference on Neural Information Processing Systems. Vancouver, Canada, 2006: 281-288, 2007. |
| [6] | DEAN J, GHEMAWAT S . Mapreduce: Simplified Data Processing on Large Clusters. Communications of the ACM, 51(1):107-113, 2008. |
| [7] | LEE K H, LEE Y, CHOI H , et al. Parallel Data Processing with MapReduce: a Survey[J]. ACM SIGMOD Record, 2012,40(4):11-20. DOI: 10.1145/2094114.2094118 |
| [8] | KOLIOPOULOS A-K, YIAPANIS P, TEKINER F, et al. A Parallel Distributed Weka Framework for Big Data Mining Using Spark [C]//IEEE International Congress on Big Data. New York, USA, 2015. DOI 10.1109/BigDataCongress.2015.12 |
| [9] | COX L A . Data Mining and Causal Modeling of Customer Behaviors[J]. Telecommunication Systems, 2002,21(2/3/4):349-381. DOI: 10.1023/A:1020911018130 |
| [10] | ROSSET S, NEUMANN E. Integrating Customer Value Considerations into Predictive Modeling [C]//Third IEEE International Conference on Data Mining, Melbourne, USA, 2003: 283-290. DOI: 10.1109/ICDM.2003.1250931 |
| [11] | NATH S V, BEHARA R S. Customer Churn Analysis in the Wireless Industry:A Data Mining Approach [C]//Annual Meeting of the Decision Sciences Institute. China, 2003: 505-510 |
| [12] | SHVACHKO K, KUANG H R, RADIA S, et al. The Hadoop Distributed File System [C]//IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, USA, 2010: 1-10. DOI: 10.1109/MSST.2010.5496972 |
| [13] | DEAN J, GHEMAWAT S . Mapreduce: Simplified Data Processing on Large Clusters[J]. Communications of the ACM, 2008, 51(1): 107-113. ACM, 2008 |
| [14] | MYERS J L, WELL A D . Research Design and Statistical Analysis[M]. 2nd ed.Mahwah, USA: Lawrence Erlbaum Associates, 2010 |
| [15] | BREIMAN L . Random Forests[J]. Machine Learning, 2001,45(1):5-32. DOI: 10.1023/A:1010933404324 |
| [16] | FENG J, ZHOU Z-H. Deep Forest: Towards an Alternative to Deep Neural Networks [C]//Twenty - Sixth International Joint Conference on Artificial Intelligence. Melbourne, Australia, 2017: 3553-3559 |
| [17] | BA L J, CARUANA R. Do Deep Nets Really Need to be Deep? [C]//Advances in Neural Information Processing Systems. Red Hook, USA: Curran Associates, 2013: 2654-2662 |
| [18] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks [C]//International Conference on Neural Information Processing Systems. Doha, Qatar, 2012: 1097-1105 |
| [19] | ZHOU Z H . Ensemble Methods: Foundations and Algorithms[M]. London, UK: Taylor & Francis, 2012 |
| [20] | LIU F T, KAI M T, ZHOU Z H. Isolation Forest [C]//Eighth IEEE International Conference on Data Mining. Miami, USA, 2009: 413-422 |
| No related articles found! |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||