ZTE Communications ›› 2019, Vol. 17 ›› Issue (1): 31-37.DOI: 10.12142/ZTECOM.201901006
• Special Topic • Previous Articles Next Articles
FANG Yuming, ZHANG Xiaoqiang
Received:2018-07-19
Online:2019-02-20
Published:2019-11-14
About author:FANG Yuming (fa0001ng@e.ntu.edu.sg) received his Ph.D. degree from Nanyang Technological University, Singapore, M.S. degree from Beijing University of Technology, China, and B.E. degree from Sichuan University, China. Currently, he is a professor in the School of Information Management, Jiangxi University of Finance and Economics, China. He serves as an associate editor of IEEE Access and is on the editorial board of Signal Processing: Image Communication. His research interests include visual attention modeling, visual quality assessment, image retargeting, computer vision, 3D image/video processing, etc.|ZHANG Xiaoqiang is currently pursuing the master’s degree with the School of Information Technology, Jiangxi University of Finance and Economics, China. His research interests include saliency detection, computer vision, machine learning, and deep learning.
FANG Yuming, ZHANG Xiaoqiang. Visual Attention Modeling inCompressed Domain:From Image Saliency Detection toVideo Saliency Detection[J]. ZTE Communications, 2019, 17(1): 31-37.
Add to citation manager EndNote|Ris|BibTeX
URL: http://zte.magtechjournal.com/EN/10.12142/ZTECOM.201901006

Figure 1. Saliency estimation results [16] on the public database Densely Annotated Video Segmentation (DAVIS) [17]. From the ?rst column to the last column: original images, saliency maps, and ground truth maps.
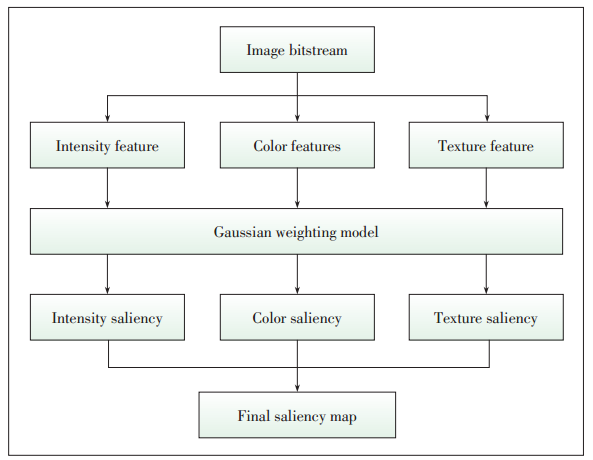
Figure 2. The framework of the model proposed in [6].

Figure 3. Saliency estimation results [6] on the public database in [49]. The ?rst row is original images, while the second row represents saliency maps.
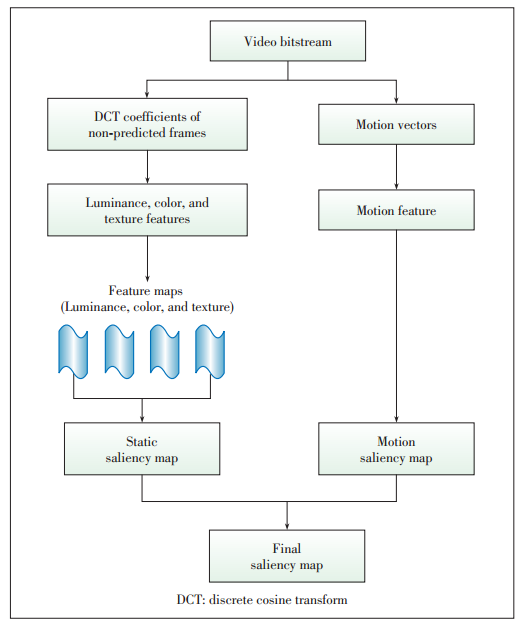
Figure 4. The framework of the model proposed by [43].

Figure 5. Saliency estimation results [43] on the public database Densely Annotated Video Segmentation (DAVIS) [17]. The ?rst row is original images, while the second row represents saliency maps.
| [1] | JAMES W . The Principles of Psychology[M]. England: Read Books Ltd, 2013 |
| [2] | NOTHDURFT H C . Salience of Feature Contrast[M] //NOTHDURFT H C. eds. Neurobiology of Attention. Amsterdam, Netherlands: Elsevier, 2005: 233-239. DOI: 10.1016/b978-012375731-9/50042-2 |
| [3] | ITTI L, KOCH C . Computational Modelling of Visual Attention[J]. Nature Reviews Neuroscience, 2001,2(3):194-203. DOI: 10.1038/35058500 |
| [4] | MAHADEVAN V, VASCONCELOS N . Saliency-Based Discriminant Tracking [C]//IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 1007-1013. DOI: 10.1109/CVPR.2009.5206573 |
| [5] | MA C, MIAO Z J, ZHANG X P , et al. A Saliency Prior Context Model for Real-Time Object Tracking[J]. IEEE Transactions on Multimedia, 2017,19(11):2415-2424. DOI: 10.1109/tmm.2017.2694219 |
| [6] |
FANG Y M, CHEN Z Z, LIN W S , et al. Saliency Detection in the Compressed Domain for Adaptive Image Retargeting[J]. IEEE Transactions on Image Processing, 2012,21(9):3888-3901. DOI: 10.1109/tip.2012.2199126
DOI URL |
| [7] | GUO M W, ZHAO Y Z, ZHANG C B , et al. Fast Object Detection Based on Selective Visual Attention[J]. Neurocomputing, 2014,144:184-197. DOI: 10.1016/j.neucom.2014.04.054 |
| [8] |
REN Z X, GAO S H, CHIA L T , et al. Region-Based Saliency Detection and Its Application in Object Recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2014,24(5):769-779. DOI: 10.1109/tcsvt.2013. 2280096
DOI URL |
| [9] | ZHAO R, WANLI O Y, WANG X G . Unsupervised Salience Learning for Person Re-Identification [C]//IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 3586-3593. DOI: 10.1109/CVPR.2013.460 |
| [10] | HOU Y H, WANG P C, XIANG W , et al. A Novel Rate Control Algorithm for Video Coding Based on fuzzy-PID Controller[J]. Signal, Image and Video Processing, 2015,9(4):875-884. DOI: 10.1007/s11760-013-0518-2 |
| [11] |
CULIBRK D, MIRKOVIC M, ZLOKOLICA V , et al. Salient Motion Features for Video Quality Assessment[J]. IEEE Transactions on Image Processing, 2011,20(4):948-958. DOI: 10.1109/tip.2010.2080279
DOI URL |
| [12] |
LIU H T, HEYNDERICKX I . Visual Attention in Objective Image Quality Assessment: Based on Eye-Tracking Data[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2011,21(7):971-982. DOI: 10.1109/tcsvt.2011.2133770
DOI URL |
| [13] |
FENG X, LIU T, YANG D , et al. Saliency Inspired Full-Reference Quality Metrics for Packet-Loss-Impaired Video[J]. IEEE Transactions on Broadcasting, 2011,57(1):81-88. DOI: 10.1109/tbc.2010.2092150
DOI URL |
| [14] | JI Q G, FANG Z D, XIE Z H , et al. Video Abstraction Based on the Visual Attention Model and Online Clustering[J]. Signal Processing: Image Communication, 2013,28(3):241-253. DOI: 10.1016/j.image.2012.11.008 |
| [15] |
MISHRA A K, ALOIMONOS Y, CHEONG L F , et al. Active Visual Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012,34(4):639-653. DOI: 10.1109/tpami.2011.171
DOI URL |
| [16] |
FANG Y M, WANG Z, LIN W S , et al. Video Saliency Incorporating Spatiotemporal Cues and Uncertainty Weighting[J]. IEEE Transactions on Image Processing, 2014,23(9):3910-3921. DOI: 10.1109/tip.2014.2336549
DOI URL |
| [17] | PERAZZI F, PONT-TUSET J, MCWILLIAMS B , et al. A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation [C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 724-732. DOI: 10.1109/CVPR.2016.85 |
| [18] | ITTI L, KOCH C, NIEBUR E . A Model of Saliency-Based Visual Attention for Rapid Scene Analysis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998,20(11):1254-1259. DOI: 10.1109/34.730558 |
| [19] | HAREL J, KOCH C, PERONA P. Graph-Based Visual Saliency [M]//Advances in Neural Information Processing Systems 19. Cambridge, USA: The MIT Press, 2007: 545-552. DOI: 10.7551/mitpress/7503.003.0073 |
| [20] | YANG C, ZHANG L H, LU H C , et al. Saliency Detection Via Graph-Based Manifold Ranking [C]//IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 3166-3173. DOI: 10.1109/CVPR.2013.407 |
| [21] | LI C Y, YUAN Y C, CAI W D , et al. Robust Saliency Detection Via Regularized Random Walks Ranking [C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, 2015: 2710-2717. DOI: 10.1109/CVPR.2015.7298887 |
| [22] | QIN Y, LU H C, XU Y Q , et al. Saliency Detection Via Cellular Automata [C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, 2015: 110-119. DOI: 10.1109/CVPR.2015.7298606 |
| [23] | TONG N, LU H C, RUAN X , et al. Salient Object Detection Via Bootstrap Learning [C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, 2015: 1884-1892. DOI: 10.1109/CVPR.2015.7298798 |
| [24] | TU W C, HE S F, YANG Q X , et al. Real-Time Salient Object Detection with a Minimum Spanning Tree [C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 2334-2342. DOI: 10.1109/CVPR.2016.256 |
| [25] | WANG L J, LU H C, RUAN X , et al. Deep Networks for Saliency Detection Via Local Estimation and Global Search [C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, 2015: 3183-3192. DOI: 10.1109/CVPR.2015.7298938 |
| [26] | ZHANG P P, WANG D, LU H C , et al. Learning Uncertain Convolutional Features for Accurate Saliency Detection [C]//IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 212-221. DOI: 10.1109/ICCV.2017.32 |
| [27] | YUAN Y C, LI C Y, KIM J , et al. Reversion Correction and Regularized Random Walk Ranking for Saliency Detection[J]. IEEE Transactions on Image Processing, 2018,27(3):1311-1322. DOI: 10.1109/tip.2017.2762422 |
| [28] | KIM H, KIM Y, SIM J Y , et al. Spatiotemporal Saliency Detection for Video Sequences Based on Random Walk with Restart[J]. IEEE Transactions on Image Processing, 2015,24(8):2552-2564. DOI: 10.1109/tip.2015.2425544 |
| [29] | XI T, ZHAO W, WANG H , et al. Salient Object Detection with Spatiotemporal Background Priors for Video[J]. IEEE Transactions on Image Processing, 2017,26(7):3425-3436. DOI: 10.1109/tip.2016.2631900 |
| [30] | AYTEKIN C, POSSEGGER H, MAUTHNER T , et al. Spatiotemporal Saliency Estimation by Spectral Foreground Detection[J]. IEEE Transactions on Multimedia, 2018,20(1):82-95. DOI: 10.1109/tmm.2017.2713982 |
| [31] | CHEN C, LI S, WANG Y G , et al. Video Saliency Detection Via Spatial-Temporal Fusion and Low-Rank Coherency Diffusion[J]. IEEE Transactions on Image Processing, 2017,26(7):3156-3170. DOI: 10.1109/tip.2017.2670143 |
| [32] |
FANG Y M, LIN W S, LEE B S , et al. Bottom-Up Saliency Detection Model Based on Human Visual Sensitivity and Amplitude Spectrum[J]. IEEE Transactions on Multimedia, 2012,14(1):187-198. DOI: 10.1109/tmm.2011. 2169775
DOI URL |
| [33] |
FANG Y M, WANG J L, NARWARIA M , et al. Saliency Detection for Stereoscopic Images[J]. IEEE Transactions on Image Processing, 2014,23(6):2625-2636. DOI: 10.1109/tip.2014.2305100
DOI URL |
| [34] | FANG Y M, ZHANG C, LI J , et al. Visual Attention Modeling for Stereoscopic Video: A Benchmark and Computational Model[J]. IEEE Transactions on Image Processing, 2017,26(10):4684-4696. DOI: 10.1109/tip.2017.2721112 |
| [35] |
MUTHUSWAMY K, RAJAN D . Salient Motion Detection in Compressed Domain[J]. IEEE Signal Processing Letters, 2013,20(10):996-999. DOI: 10.1109/lsp.2013.2277884
DOI URL |
| [36] | KHATOONABADI S H, VASCONCELOS N, BAJICI V , et al. How Many Bits does it Take for a Stimulus to be Salient? [C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, 2015: 5501-5510. DOI: 10.1109/CVPR.2015.7299189 |
| [37] | KHATOONABADI S H, BAJICI V, SHAN Y F . Compressed-Domain Correlates of Human Fixations in Dynamic Scenes[J]. Multimedia Tools and Applications, 2015,74(22):10057-10075. DOI: 10.1007/s11042-015-2802-3 |
| [38] | LI Y J, LI Y S . A Fast and Efficient Saliency Detection Model in Video Compressed-Domain for Human Fixations Prediction[J]. Multimedia Tools and Applications, 2017,76(24):26273-26295. DOI: 10.1007/s11042-016-4118-3 |
| [39] | LI Y J, LI Y S, LIU W J , et al. Human Fixation Detection Model in Video Compressed Domain Based on Markov Random Field[J]. Journal of Electronic Imaging, 2017,26(1):013008. DOI: 10.1117/1.jei.26.1.013008 |
| [40] | XU M, JIANG L, SUN X Y , et al. Learning to Detect Video Saliency with HEVC Features[J]. IEEE Transactions on Image Processing, 2017,26(1):369-385. DOI: 10.1109/tip.2016.2628583 |
| [41] | JIAN M W, QI Q, DONG J Y , et al. Integrating QDWD with Pattern Distinctness and Local Contrast for Underwater Saliency Detection[J]. Journal of Visual Communication and Image Representation, 2018,53:31-41. DOI: 10.1016/j.jvcir.2018.03.008 |
| [42] | AMMAR M, MITREA M, HASNAOUI M , et al. MPEG-4 AVC Stream-Based Saliency Detection. Application to Robust Watermarking[J]. Signal Processing: Image Communication, 2018,60:116-130. DOI: 10.1016/j.image.2017. 09.007 |
| [43] |
FANG Y M, LIN W S, CHEN Z Z , et al. A Video Saliency Detection Model in Compressed Domain[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2014,24(1):27-38. DOI: 10.1109/tcsvt.2013.2273613
DOI URL |
| [44] | LI J, XIA C Q, CHEN X W . A Benchmark Dataset and Saliency-Guided Stacked Autoencoders for Video-Based Salient Object Detection[J]. IEEE Transactions on Image Processing, 2018,27(1):349-364. DOI: 10.1109/tip.2017.2762594 |
| [45] | ZHANG J M, SCLAROFF S, LIN Z , et al. Minimum Barrier Salient Object Detection at 80 FPS [C]//IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 2015: 1404-1412. DOI: 10.1109/ICCV.2015.165 |
| [46] | PENG H W, LI B, LING H B , et al. Salient Object Detection via Structured Matrix Decomposition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,39(4):818-832. DOI: 10.1109/tpami.2016.2562626 |
| [47] |
LI J, LEVINE M D, AN X J , et al. Visual Saliency Based on Scale-Space Analysis in the Frequency Domain[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013,35(4):996-1010. DOI: 10.1109/tpami.2012.147
DOI URL |
| [48] | AGARWAL G, ANBU A, SINHA A . A Fast Algorithm to Find the Region-of-Interest in the Compressed MPEG Domain [C]//International Conference on Multimedia and Expo. (ICME’03), Baltimore, USA, 2003: 133-136. DOI: 10.1109/ICME.2003.1221571 |
| [49] | ACHANTA R, HEMAMI S, ESTRADA F , et al. Frequency-Tuned Salient Region Detection [C]//IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 1597-1604. DOI: 10.1109/CVPR.2009.5206596 |
| [50] | CHAMARET C, CHEVET J C, LE MEUR O . Spatio-Temporal Combination of Saliency Maps and Eye-Tracking Assessment of Different Strategies [C]//IEEE International Conference on Image Processing, Hong Kong, China, 2010: 1077-1080. DOI: 10.1109/ICIP.2010.5651381 |
| [51] | GUO C L, ZHANG L M . A Novel Multiresolution Spatiotemporal Saliency Detection Model and Its Applications in Image and Video Compression[J]. IEEE Transactions on Image Processing, 2010,19(1):185-198. DOI: 10.1109/tip.2009.2030969 |
| [52] |
LE MEUR O, LE CALLET P, BARBA D . Predicting Visual Fixations on Video Based on Low-Level Visual Features[J]. Vision Research, 2007,47(19):2483-2498. DOI: 10.1016/j.visres.2007.06.015
DOI URL |
| [53] | MAHADEVAN V, VASCONCELOS N . Spatiotemporal Saliency in Dynamic Scenes[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010,32(1):171-177. DOI: 10.1109/tpami.2009.112 |
| [54] | STOCKER A A, SIMONCELLI E P . Noise Characteristics and Prior Expectations in Human Visual Speed Perception[J]. Nature Neuroscience, 2006,9(4):578-585. DOI: 10.1038/nn1669 |
| [55] | BANERJEE J C . Gestalt Theory of Perception (M)// Encyclopaedic Dictionary of Psychological Terms. New Delhi, India: MD Publications Pvt. Ltd., 1994: 107-109 |
| [56] | STEVENSON H . Emergence: The Gestalt Approach to Change [EB/OL]. (2012). http://www.clevelandconsultinggroup.com/articles/emergence-gestalt-approach-to-change.php |
| [1] | Ruimin Hu, Rui Zhong, Zhongyuan Wang, and Zhen Han. 3D Perception Algorithms: Towards Perceptually Driven Compression of 3D Video [J]. ZTE Communications, 2013, 11(1): 11-16. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

